first commit
This commit is contained in:
commit
f54fbb05aa
21
LICENSE
Normal file
21
LICENSE
Normal file
@ -0,0 +1,21 @@
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2019 Lam1360
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
67
README.md
Normal file
67
README.md
Normal file
@ -0,0 +1,67 @@
|
||||
# YOLOv3-model-pruning
|
||||
|
||||
用 YOLOv3 模型在一个开源的人手检测数据集 [oxford hand](http://www.robots.ox.ac.uk/~vgg/data/hands/) 上做人手检测,并在此基础上做模型剪枝。对于该数据集,对 YOLOv3 进行 channel pruning 之后,模型的参数量、模型大小减少 80% ,FLOPs 降低 70%,前向推断的速度可以达到原来的 200%,同时可以保持 mAP 基本不变。
|
||||
|
||||
## 环境
|
||||
|
||||
Python3.6, Pytorch 1.0及以上
|
||||
|
||||
YOLOv3 的实现参考了 eriklindernoren 的 [PyTorch-YOLOv3](https://github.com/eriklindernoren/PyTorch-YOLOv3) ,因此代码的依赖环境也可以参考其 repo
|
||||
|
||||
## 数据集准备
|
||||
|
||||
1. 下载[数据集](http://www.robots.ox.ac.uk/~vgg/data/hands/downloads/hand_dataset.tar.gz),得到压缩文件
|
||||
2. 将压缩文件解压到 data 目录,得到 hand_dataset 文件夹
|
||||
3. 在 data 目录下执行 converter.py,生成 images、labels 文件夹和 train.txt、valid.txt 文件。训练集中一共有 4807 张图
|
||||
片,测试集中一共有 821 张图片
|
||||
|
||||
## 正常训练(Baseline)
|
||||
|
||||
```bash
|
||||
python train.py --model_def config/yolov3-hand.cfg
|
||||
```
|
||||
|
||||
## 剪枝算法介绍
|
||||
|
||||
本代码基于论文 [Learning Efficient Convolutional Networks Through Network Slimming (ICCV 2017)](http://openaccess.thecvf.com/content_iccv_2017/html/Liu_Learning_Efficient_Convolutional_ICCV_2017_paper.html) 进行改进实现的 channel pruning算法,类似的代码实现还有这个 [yolov3-network-slimming](https://github.com/talebolano/yolov3-network-slimming)。原始论文中的算法是针对分类模型的,基于 BN 层的 gamma 系数进行剪枝的。
|
||||
|
||||
### 剪枝算法的大概步骤
|
||||
|
||||
以下只是算法的大概步骤,具体实现过程中还要做 s 参数的尝试或者需要进行迭代式剪枝等。
|
||||
|
||||
1. 进行稀疏化训练
|
||||
|
||||
```bash
|
||||
python train.py --model_def config/yolov3-hand.cfg -sr --s 0.01
|
||||
```
|
||||
|
||||
2. 基于 test_prune.py 文件进行剪枝,得到剪枝后的模型
|
||||
|
||||
3. 对剪枝后的模型进行微调
|
||||
```bash
|
||||
python train.py --model_def config/prune_yolov3-hand.cfg -pre checkpoints/prune_yolov3_ckpt.pth
|
||||
```
|
||||
|
||||
### 剪枝前后的对比
|
||||
|
||||
1. 下图为对部分卷积层进行剪枝前后通道数的变化:
|
||||
|
||||
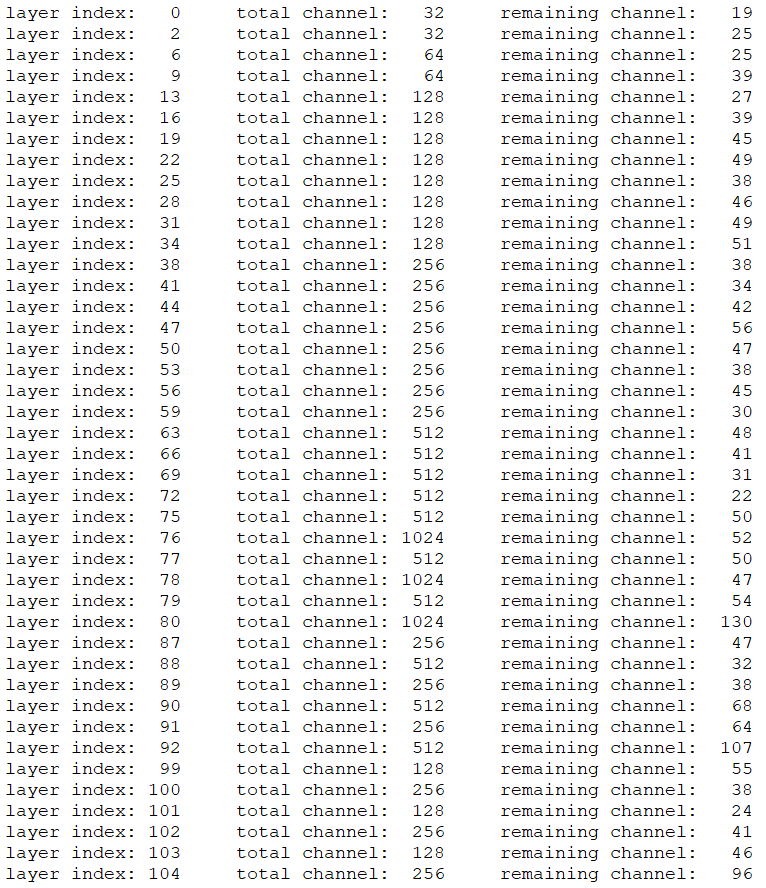
|
||||
> 部分卷积层的通道数大幅度减少
|
||||
|
||||
2. 剪枝前后指标对比:
|
||||
|
||||
| | 参数数量 | 模型体积 |Flops | 前向推断耗时(2070 TI) | mAP |
|
||||
| :------------: | :------:| :-----: | :---: | :-------------------: | :----: |
|
||||
| Baseline (416) | 61.5M | 246.4MB |32.8B | 15.0 ms | 0.7692 |
|
||||
| Prune (416) | 10.9M | 43.6MB | 9.6B | 7.7 ms | 0.7722 |
|
||||
| Finetune (416) | 同上 | 同上 | 同上 | 同上 | 0.7750 |
|
||||
|
||||
> 加入稀疏正则项之后,mAP 反而更高了(在实验过程中发现,其实 mAP上下波动 0.02 是正常现象),因此可以认为稀疏训练得到的 mAP 与正常训练几乎一致。将 prune 后得到的模型进行 finetune 并没有明显的提升,因此剪枝三步可以直接简化成两步。剪枝前后模型的参数量、模型大小降为原来的 1/6 ,FLOPs 降为原来的 1/3,前向推断的速度可以达到原来的 2 倍,同时可以保持 mAP 基本不变。*需要明确的是,上面表格中剪枝的效果是只是针对该数据集的,不一定能保证在其他数据集上也有同样的效果*
|
||||
|
||||
3. 剪枝后模型的测试:
|
||||
|
||||
Prune 模型的权重已放在百度网盘上 ([提取码: gnzx](https://pan.baidu.com/s/13Ycj7JccBHWYF590bgFRxQ)),可以通过执行以下代码进行测试:
|
||||
```bash
|
||||
python test.py --model_def config/prune_yolov3-hand.cfg --weights_path weights/prune_yolov3_ckpt.pth --data_config config/oxfordhand.data --class_path data/oxfordhand.names --conf_thres 0.01
|
||||
```
|
||||
BIN
__pycache__/debug_utils.cpython-38.pyc
Normal file
BIN
__pycache__/debug_utils.cpython-38.pyc
Normal file
Binary file not shown.
BIN
__pycache__/models.cpython-38.pyc
Normal file
BIN
__pycache__/models.cpython-38.pyc
Normal file
Binary file not shown.
BIN
__pycache__/models.cpython-39.pyc
Normal file
BIN
__pycache__/models.cpython-39.pyc
Normal file
Binary file not shown.
759
__pycache__/prune_0.58_yolov3-person.cfg
Normal file
759
__pycache__/prune_0.58_yolov3-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=31
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=35
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=55
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=38
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=72
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=79
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=80
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=76
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=85
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=78
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=62
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=83
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=59
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=33
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=31
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=30
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=21
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=30
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=15
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=73
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=35
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=14
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=71
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=226
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=338
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=214
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=337
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=253
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=898
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=179
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=224
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=141
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=235
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=153
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=432
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=96
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=151
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=89
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=159
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=80
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=195
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
BIN
__pycache__/prune_0.58_yolov3_ckpt_99_04111754.pth
Normal file
BIN
__pycache__/prune_0.58_yolov3_ckpt_99_04111754.pth
Normal file
Binary file not shown.
BIN
__pycache__/test.cpython-38.pyc
Normal file
BIN
__pycache__/test.cpython-38.pyc
Normal file
Binary file not shown.
BIN
__pycache__/test.cpython-39.pyc
Normal file
BIN
__pycache__/test.cpython-39.pyc
Normal file
Binary file not shown.
759
config/1w_prune_0.6_yolov3-person.cfg
Normal file
759
config/1w_prune_0.6_yolov3-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=30
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=54
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=63
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=90
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=107
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=118
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=119
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=113
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=112
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=120
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=113
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=55
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=112
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=147
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=157
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=149
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=155
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=166
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=164
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=66
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=56
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=43
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=34
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=173
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=287
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=139
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=182
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=212
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=207
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=185
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=249
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=156
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=244
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=188
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=125
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=105
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=90
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=91
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=127
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=103
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=113
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/1w_prune_0.7_yolov3-person.cfg
Normal file
759
config/1w_prune_0.7_yolov3-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=28
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=31
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=50
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=62
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=70
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=98
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=112
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=110
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=109
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=105
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=114
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=105
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=38
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=69
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=113
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=114
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=119
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=110
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=127
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=127
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=35
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=18
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=16
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=13
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=122
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=170
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=74
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=98
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=140
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=108
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=167
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=178
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=181
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=160
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=79
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=101
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=69
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=79
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=99
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=92
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=75
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/1w_prune_0.875_yolov3-person.cfg
Normal file
759
config/1w_prune_0.875_yolov3-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=20
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=29
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=35
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=50
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=38
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=50
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=58
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=65
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=74
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=66
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=47
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=27
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=21
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=21
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=17
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=20
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=19
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=18
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=11
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=3
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=2
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=55
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=39
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=34
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=42
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=56
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=16
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=86
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=46
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=47
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=55
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=92
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=23
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=75
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=40
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=47
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=54
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=67
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=41
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/1w_prune_0.8_yolov3-person.cfg
Normal file
759
config/1w_prune_0.8_yolov3-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=27
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=29
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=47
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=60
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=53
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=83
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=96
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=100
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=96
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=93
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=100
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=89
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=14
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=39
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=50
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=66
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=69
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=55
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=72
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=63
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=21
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=5
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=8
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=4
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=65
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=79
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=39
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=56
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=83
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=34
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=125
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=90
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=84
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=106
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=121
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=39
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=94
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=49
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=63
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=71
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=85
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=54
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/6.8_1w_prune_0.5_yolov3-person.cfg
Normal file
759
config/6.8_1w_prune_0.5_yolov3-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=31
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=57
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=63
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=106
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=112
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=120
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=122
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=119
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=116
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=124
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=117
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=62
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=145
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=171
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=187
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=174
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=187
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=193
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=195
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=102
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=118
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=84
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=85
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=230
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=399
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=207
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=294
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=271
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=305
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=208
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=320
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=185
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=307
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=208
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=191
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=111
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=112
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=107
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=159
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=110
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=142
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
794
config/create_hand_model.sh
Normal file
794
config/create_hand_model.sh
Normal file
@ -0,0 +1,794 @@
|
||||
#!/bin/bash
|
||||
|
||||
NUM_CLASSES=$1
|
||||
|
||||
echo "
|
||||
[net]
|
||||
# Testing
|
||||
#batch=1
|
||||
#subdivisions=1
|
||||
# Training
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation = 1.5
|
||||
exposure = 1.5
|
||||
hue=.1
|
||||
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches = 500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
######################
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=$(expr 3 \* $(expr $NUM_CLASSES \+ 5))
|
||||
activation=linear
|
||||
|
||||
|
||||
[yolo]
|
||||
mask = 6,7,8
|
||||
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=$NUM_CLASSES
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh = .7
|
||||
truth_thresh = 1
|
||||
random=1
|
||||
|
||||
|
||||
[route]
|
||||
layers = -4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers = -1, 61
|
||||
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=$(expr 3 \* $(expr $NUM_CLASSES \+ 5))
|
||||
activation=linear
|
||||
|
||||
|
||||
[yolo]
|
||||
mask = 3,4,5
|
||||
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=$NUM_CLASSES
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh = .7
|
||||
truth_thresh = 1
|
||||
random=1
|
||||
|
||||
|
||||
|
||||
[route]
|
||||
layers = -4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers = -1, 36
|
||||
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=$(expr 3 \* $(expr $NUM_CLASSES \+ 5))
|
||||
activation=linear
|
||||
|
||||
|
||||
[yolo]
|
||||
mask = 0,1,2
|
||||
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=$NUM_CLASSES
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh = .7
|
||||
truth_thresh = 1
|
||||
random=1
|
||||
" >> yolov3-test.cfg
|
||||
759
config/ds8_1w_prune_0.0_yolov3-ds8-person.cfg
Normal file
759
config/ds8_1w_prune_0.0_yolov3-ds8-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=62
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=278
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=252
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=254
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=200
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=242
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=446
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=236
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=390
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=219
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=193
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=215
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=355
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=182
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=281
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=125
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=220
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=109
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=213
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=100
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=151
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=70
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=231
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=28
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=27
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=58
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=60
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=126
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=112
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=119
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=84
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=147
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=255
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=137
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=181
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=113
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=23
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=160
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=260
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=140
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=208
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=109
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=33
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=98
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=170
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=84
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=132
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=58
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=170
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/ds8_1w_prune_0.7_ckpt_99_06091301yolov3-ds8-person.cfg
Normal file
759
config/ds8_1w_prune_0.7_ckpt_99_06091301yolov3-ds8-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=28
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=27
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=58
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=60
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=132
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=111
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=120
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=92
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=148
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=253
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=139
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=174
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=118
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=22
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=159
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=260
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=137
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=208
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=105
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=32
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=99
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=169
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=85
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=134
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=61
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=161
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=27
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=26
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=58
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=57
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=86
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=54
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=18
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=5
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=85
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=95
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=72
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=70
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=23
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=147
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=180
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=123
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=132
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=89
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=32
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=90
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=135
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=76
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=108
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=53
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=156
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/ds8_1w_prune_0.8_ckpt_99_05181112yolov3-ds8-person.cfg
Normal file
759
config/ds8_1w_prune_0.8_ckpt_99_05181112yolov3-ds8-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=9
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=8
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=14
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=15
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=89
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=80
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=78
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=102
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=109
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=199
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=102
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=187
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=106
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=206
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=49
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=105
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=48
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=111
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=44
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=123
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=27
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=55
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=23
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=57
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=16
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=99
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/ds8_1w_prune_0.8_ckpt_99_06091301yolov3-ds8-person.cfg
Normal file
759
config/ds8_1w_prune_0.8_ckpt_99_06091301yolov3-ds8-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=26
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=26
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=58
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=55
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=92
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=47
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=28
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=4
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=83
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=88
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=72
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=69
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=69
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=21
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=141
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=184
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=117
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=146
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=82
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=31
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=92
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=141
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=78
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=106
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=54
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=151
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/ds_1w_prune_0.1_xs_min_loss_yolov3-ds-person.cfg
Normal file
759
config/ds_1w_prune_0.1_xs_min_loss_yolov3-ds-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=28
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=28
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=55
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=56
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=453
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=906
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=454
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=889
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=450
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=984
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=230
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=450
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=227
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=441
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=227
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=509
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=113
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=227
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=112
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=224
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=112
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/ds_1w_prune_0.5_xs_best_mAP_yolov3-ds-person.cfg
Normal file
759
config/ds_1w_prune_0.5_xs_best_mAP_yolov3-ds-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=28
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=30
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=61
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=60
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=247
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=380
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=199
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=365
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=200
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=187
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=219
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=344
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=171
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=260
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=137
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=394
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=114
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=189
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=94
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=144
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=54
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=251
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/ds_1w_prune_0.6_xs_best_mAP_yolov3-ds-person.cfg
Normal file
759
config/ds_1w_prune_0.6_xs_best_mAP_yolov3-ds-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=26
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=29
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=60
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=58
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=177
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=269
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=157
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=247
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=160
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=83
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=192
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=295
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=146
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=213
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=114
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=305
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=110
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=159
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=82
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=121
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=53
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=247
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/ds_1w_prune_0.6_yolov3-ds-person.cfg
Normal file
759
config/ds_1w_prune_0.6_yolov3-ds-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=29
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=29
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=57
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=59
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=203
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=299
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=172
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=315
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=197
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=85
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=205
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=300
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=160
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=212
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=115
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=139
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=107
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=163
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=81
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=122
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=52
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=202
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/ds_1w_prune_0.7_ckpt_99_05181112yolov3-ds-person.cfg
Normal file
759
config/ds_1w_prune_0.7_ckpt_99_05181112yolov3-ds-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=27
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=27
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=55
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=55
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=204
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=127
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=198
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=121
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=50
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=179
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=241
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=119
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=167
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=100
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=41
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=99
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=145
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=76
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=112
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=50
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=156
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/ds_1w_prune_0.7_xs_best_mAP_yolov3-ds-person.cfg
Normal file
759
config/ds_1w_prune_0.7_xs_best_mAP_yolov3-ds-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=20
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=25
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=54
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=53
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=131
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=205
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=121
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=180
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=108
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=28
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=165
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=233
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=124
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=170
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=100
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=50
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=98
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=146
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=77
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=115
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=50
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=224
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/ds_1w_prune_0.85_ckpt_99_05181112yolov3-ds-person.cfg
Normal file
759
config/ds_1w_prune_0.85_ckpt_99_05181112yolov3-ds-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=15
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=22
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=46
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=48
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=69
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=55
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=43
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=46
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=48
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=112
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=116
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=68
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=69
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=67
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=27
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=65
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=60
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=51
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=54
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=108
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/ds_1w_prune_0.8_ckpt_99_05181112yolov3-ds-person.cfg
Normal file
759
config/ds_1w_prune_0.8_ckpt_99_05181112yolov3-ds-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=19
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=23
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=47
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=49
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=90
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=90
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=66
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=76
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=68
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=147
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=160
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=98
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=105
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=85
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=28
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=83
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=112
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=65
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=75
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=34
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=114
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/ds_1w_prune_0.8_xs_best_mAP_yolov3-ds-person.cfg
Normal file
759
config/ds_1w_prune_0.8_xs_best_mAP_yolov3-ds-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=17
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=23
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=47
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=49
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=89
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=87
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=74
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=72
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=23
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=141
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=169
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=91
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=98
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=82
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=29
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=84
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=108
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=65
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=74
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=36
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=130
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/ds_1w_prune_0.8_xs_min_loss_yolov3-ds-person.cfg
Normal file
759
config/ds_1w_prune_0.8_xs_min_loss_yolov3-ds-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=7
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=3
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=6
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=9
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=56
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=106
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=61
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=96
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=58
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=342
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=33
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=55
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=48
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=25
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=365
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=21
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=27
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=8
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=36
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=14
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=244
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/ds_1w_prune_0.9_xs_best_mAP_yolov3-ds-person.cfg
Normal file
759
config/ds_1w_prune_0.9_xs_best_mAP_yolov3-ds-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=16
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=19
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=42
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=47
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=45
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=26
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=25
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=21
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=36
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=22
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=78
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=49
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=49
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=41
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=52
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=25
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=35
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=21
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=33
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=34
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=27
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=83
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/ds_1w_prune_0.9_xs_min_loss_yolov3-ds-person.cfg
Normal file
759
config/ds_1w_prune_0.9_xs_min_loss_yolov3-ds-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=3
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=4
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=6
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=9
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=23
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=19
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=30
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=21
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=148
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=8
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=15
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=10
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=13
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=10
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=245
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=4
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=5
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=2
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=13
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=3
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=234
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
4
config/oxfordhand.data
Normal file
4
config/oxfordhand.data
Normal file
@ -0,0 +1,4 @@
|
||||
classes= 1
|
||||
train=data/train.txt
|
||||
valid=data/valid.txt
|
||||
names=data/oxfordhand.names
|
||||
4
config/person.data
Normal file
4
config/person.data
Normal file
@ -0,0 +1,4 @@
|
||||
classes= 1
|
||||
train=data/train.txt
|
||||
valid=data/valid.txt
|
||||
names=data/person.names
|
||||
759
config/prune_0.2_yolov3-person.cfg
Normal file
759
config/prune_0.2_yolov3-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=31
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=28
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=26
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=57
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=49
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=103
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=94
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=106
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=97
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=79
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=68
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=73
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=232
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=185
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=85
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=120
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=85
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=163
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=40
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=299
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=194
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=191
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=260
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=253
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=255
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=254
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=506
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=122
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=246
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=121
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=249
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=127
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=239
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/prune_0.55_yolov3-person.cfg
Normal file
759
config/prune_0.55_yolov3-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=31
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=40
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=56
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=46
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=80
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=83
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=83
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=79
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=90
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=80
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=67
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=86
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=72
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=34
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=33
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=35
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=21
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=34
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=15
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=80
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=36
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=15
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=75
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=379
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=237
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=379
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=275
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=924
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=194
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=248
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=151
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=255
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=168
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=446
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=105
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=154
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=95
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=167
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=83
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=201
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/prune_0.58_yolov3-person.cfg
Normal file
759
config/prune_0.58_yolov3-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=31
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=35
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=55
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=38
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=72
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=79
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=80
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=76
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=85
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=78
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=62
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=83
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=59
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=33
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=31
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=30
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=21
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=30
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=15
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=73
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=35
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=14
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=71
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=226
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=338
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=214
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=337
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=253
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=898
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=179
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=224
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=141
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=235
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=153
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=432
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=96
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=151
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=89
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=159
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=80
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=195
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/prune_0.5_yolov3-person.cfg
Normal file
759
config/prune_0.5_yolov3-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=31
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=46
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=58
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=61
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=98
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=92
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=100
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=98
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=101
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=90
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=76
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=98
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=86
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=58
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=51
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=62
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=41
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=56
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=27
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=93
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=41
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=21
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=80
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=288
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=431
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=253
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=426
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=303
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=949
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=214
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=266
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=163
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=276
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=184
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=451
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=123
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=162
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=110
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=189
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=100
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=203
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/prune_0.65_yolov3-person.cfg
Normal file
759
config/prune_0.65_yolov3-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=30
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=30
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=54
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=36
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=67
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=68
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=68
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=70
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=75
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=67
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=52
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=72
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=50
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=26
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=20
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=24
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=21
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=27
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=12
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=62
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=30
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=12
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=61
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=182
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=225
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=148
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=219
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=190
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=839
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=143
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=186
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=121
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=175
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=119
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=401
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=82
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=127
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=76
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=124
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=69
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=190
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/prune_0.6_yolov3-person.cfg
Normal file
759
config/prune_0.6_yolov3-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=31
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=33
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=55
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=38
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=72
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=73
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=77
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=76
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=84
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=73
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=60
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=81
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=57
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=29
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=30
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=26
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=21
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=28
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=15
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=70
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=34
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=13
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=69
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=212
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=303
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=192
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=297
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=238
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=883
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=169
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=214
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=135
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=216
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=142
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=423
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=91
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=147
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=86
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=152
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=79
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=195
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/prune_0.7_yolov3-person.cfg
Normal file
759
config/prune_0.7_yolov3-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=30
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=28
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=52
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=30
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=63
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=63
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=62
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=63
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=60
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=47
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=62
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=42
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=25
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=18
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=21
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=19
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=25
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=11
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=55
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=27
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=9
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=52
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=147
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=139
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=114
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=157
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=141
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=787
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=116
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=147
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=109
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=123
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=101
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=380
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=67
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=111
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=63
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=104
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=62
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=185
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/prune_0.85_yolov3-hand.cfg
Normal file
759
config/prune_0.85_yolov3-hand.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=18
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=24
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=30
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=48
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=31
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=60
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=57
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=66
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=65
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=87
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=78
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=77
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=69
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=43
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=26
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=67
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=99
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=34
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=119
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=21
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=35
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=25
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=14
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=10
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=52
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=34
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=45
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=40
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=74
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=17
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=67
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=31
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=38
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=37
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=83
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=23
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=66
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=20
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=39
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=40
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=44
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=54
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/prune_yolov3-hand.cfg
Normal file
759
config/prune_yolov3-hand.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=19
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=25
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=25
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=39
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=27
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=39
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=45
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=49
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=38
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=46
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=49
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=51
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=38
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=34
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=42
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=56
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=47
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=38
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=45
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=30
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=48
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=41
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=31
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=22
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=50
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=52
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=50
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=47
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=54
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=130
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=47
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=32
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=38
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=68
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=107
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=55
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=38
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=24
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=41
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=46
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=96
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/small_ds_1w_prune_0.5_yolov3-ds-person.cfg
Normal file
759
config/small_ds_1w_prune_0.5_yolov3-ds-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=29
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=29
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=59
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=61
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=264
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=422
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=237
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=441
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=263
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=139
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=226
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=352
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=179
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=278
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=137
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=215
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=111
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=182
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=90
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=140
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=54
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=220
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
759
config/small_ds_1w_prune_0.6_yolov3-ds-person.cfg
Normal file
759
config/small_ds_1w_prune_0.6_yolov3-ds-person.cfg
Normal file
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=29
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=29
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=57
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=59
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=203
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=299
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=172
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=315
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=197
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=85
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=205
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=300
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=160
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=212
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=115
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=139
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=107
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=163
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=81
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=122
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=52
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=202
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
4
config/smallperson.data
Normal file
4
config/smallperson.data
Normal file
@ -0,0 +1,4 @@
|
||||
classes= 1
|
||||
train=data/train.txt
|
||||
valid=data/smallvalid.txt
|
||||
names=data/person.names
|
||||
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=30
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=62
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=62
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=298
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=244
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=230
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=201
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=238
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=453
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=236
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=376
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=206
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=145
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=216
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=373
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=184
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=303
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=134
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=231
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=117
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=200
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=106
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=159
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=71
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=245
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=31
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=30
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=60
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=62
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[ds_conv]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=223
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=179
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=172
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=146
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=182
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=349
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=178
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=263
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=151
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=70
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=202
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=319
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=160
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=247
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=118
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=140
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=113
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=185
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=96
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=145
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=237
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=20
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=24
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=46
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=47
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=110
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=109
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=104
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=104
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=99
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=88
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=82
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=78
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=172
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=152
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=104
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=73
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=77
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=58
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=46
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=88
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=50
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=31
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=13
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=67
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=72
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=56
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=64
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=76
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=25
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=104
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=131
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=93
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=109
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=84
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=32
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=71
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=105
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=71
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=75
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=52
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=154
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=22
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=25
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=49
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=50
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=114
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=109
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=105
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=107
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=100
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=91
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=85
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=81
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=181
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=165
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=144
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=113
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=93
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=81
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=73
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=58
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=124
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=78
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=59
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=37
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=92
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=125
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=83
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=120
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=101
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=26
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=124
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=192
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=113
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=153
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=94
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=33
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=84
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=136
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=82
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=96
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=58
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=157
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
@ -0,0 +1,759 @@
|
||||
[net]
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation=1.5
|
||||
exposure=1.5
|
||||
hue=.1
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches=500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=20
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=23
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=43
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=43
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=107
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=109
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=101
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=101
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=93
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=80
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=74
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=70
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=161
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=129
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=107
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=78
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=56
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=54
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=39
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=37
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=57
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=28
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=10
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=6
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=50
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=43
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=35
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=41
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=44
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=24
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=6,7,8
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 61
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=80
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=80
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=71
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=62
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=30
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=3,4,5
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
[route]
|
||||
layers=-4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers=-1, 36
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=56
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=64
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=56
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=57
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=48
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=145
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=0
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
[yolo]
|
||||
mask=0,1,2
|
||||
anchors=10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh=.7
|
||||
truth_thresh=1
|
||||
random=1
|
||||
|
||||
1036
config/yolov3-ds-person.cfg
Normal file
1036
config/yolov3-ds-person.cfg
Normal file
File diff suppressed because it is too large
Load Diff
1036
config/yolov3-ds8-person.cfg
Normal file
1036
config/yolov3-ds8-person.cfg
Normal file
File diff suppressed because it is too large
Load Diff
790
config/yolov3-hand.cfg
Normal file
790
config/yolov3-hand.cfg
Normal file
@ -0,0 +1,790 @@
|
||||
|
||||
[net]
|
||||
# Testing
|
||||
#batch=1
|
||||
#subdivisions=1
|
||||
# Training
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation = 1.5
|
||||
exposure = 1.5
|
||||
hue=.1
|
||||
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches = 500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
######################
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
|
||||
[yolo]
|
||||
mask = 6,7,8
|
||||
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh = .7
|
||||
truth_thresh = 1
|
||||
random=1
|
||||
|
||||
|
||||
[route]
|
||||
layers = -4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers = -1, 61
|
||||
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
|
||||
[yolo]
|
||||
mask = 3,4,5
|
||||
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh = .7
|
||||
truth_thresh = 1
|
||||
random=1
|
||||
|
||||
|
||||
|
||||
[route]
|
||||
layers = -4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers = -1, 36
|
||||
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
|
||||
[yolo]
|
||||
mask = 0,1,2
|
||||
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh = .7
|
||||
truth_thresh = 1
|
||||
random=1
|
||||
|
||||
790
config/yolov3-person.cfg
Normal file
790
config/yolov3-person.cfg
Normal file
@ -0,0 +1,790 @@
|
||||
|
||||
[net]
|
||||
# Testing
|
||||
#batch=1
|
||||
#subdivisions=1
|
||||
# Training
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation = 1.5
|
||||
exposure = 1.5
|
||||
hue=.1
|
||||
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches = 500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
######################
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
|
||||
[yolo]
|
||||
mask = 6,7,8
|
||||
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh = .7
|
||||
truth_thresh = 1
|
||||
random=1
|
||||
|
||||
|
||||
[route]
|
||||
layers = -4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers = -1, 61
|
||||
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
|
||||
[yolo]
|
||||
mask = 3,4,5
|
||||
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh = .7
|
||||
truth_thresh = 1
|
||||
random=1
|
||||
|
||||
|
||||
|
||||
[route]
|
||||
layers = -4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers = -1, 36
|
||||
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
|
||||
[yolo]
|
||||
mask = 0,1,2
|
||||
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh = .7
|
||||
truth_thresh = 1
|
||||
random=1
|
||||
|
||||
790
config/yolov3-test.cfg
Normal file
790
config/yolov3-test.cfg
Normal file
@ -0,0 +1,790 @@
|
||||
|
||||
[net]
|
||||
# Testing
|
||||
#batch=1
|
||||
#subdivisions=1
|
||||
# Training
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation = 1.5
|
||||
exposure = 1.5
|
||||
hue=.1
|
||||
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches = 500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
######################
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
|
||||
[yolo]
|
||||
mask = 6,7,8
|
||||
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh = .7
|
||||
truth_thresh = 1
|
||||
random=1
|
||||
|
||||
|
||||
[route]
|
||||
layers = -4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers = -1, 61
|
||||
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
|
||||
[yolo]
|
||||
mask = 3,4,5
|
||||
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh = .7
|
||||
truth_thresh = 1
|
||||
random=1
|
||||
|
||||
|
||||
|
||||
[route]
|
||||
layers = -4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers = -1, 36
|
||||
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=18
|
||||
activation=linear
|
||||
|
||||
|
||||
[yolo]
|
||||
mask = 0,1,2
|
||||
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=1
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh = .7
|
||||
truth_thresh = 1
|
||||
random=1
|
||||
|
||||
206
config/yolov3-tiny.cfg
Normal file
206
config/yolov3-tiny.cfg
Normal file
@ -0,0 +1,206 @@
|
||||
[net]
|
||||
# Testing
|
||||
batch=1
|
||||
subdivisions=1
|
||||
# Training
|
||||
# batch=64
|
||||
# subdivisions=2
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation = 1.5
|
||||
exposure = 1.5
|
||||
hue=.1
|
||||
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches = 500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
# 0
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=16
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
# 1
|
||||
[maxpool]
|
||||
size=2
|
||||
stride=2
|
||||
|
||||
# 2
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
# 3
|
||||
[maxpool]
|
||||
size=2
|
||||
stride=2
|
||||
|
||||
# 4
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
# 5
|
||||
[maxpool]
|
||||
size=2
|
||||
stride=2
|
||||
|
||||
# 6
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
# 7
|
||||
[maxpool]
|
||||
size=2
|
||||
stride=2
|
||||
|
||||
# 8
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
# 9
|
||||
[maxpool]
|
||||
size=2
|
||||
stride=2
|
||||
|
||||
# 10
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
# 11
|
||||
[maxpool]
|
||||
size=2
|
||||
stride=1
|
||||
|
||||
# 12
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
###########
|
||||
|
||||
# 13
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
# 14
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
# 15
|
||||
[convolutional]
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=255
|
||||
activation=linear
|
||||
|
||||
|
||||
|
||||
# 16
|
||||
[yolo]
|
||||
mask = 3,4,5
|
||||
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
|
||||
classes=80
|
||||
num=6
|
||||
jitter=.3
|
||||
ignore_thresh = .7
|
||||
truth_thresh = 1
|
||||
random=1
|
||||
|
||||
# 17
|
||||
[route]
|
||||
layers = -4
|
||||
|
||||
# 18
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
# 19
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
# 20
|
||||
[route]
|
||||
layers = -1, 8
|
||||
|
||||
# 21
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
# 22
|
||||
[convolutional]
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=255
|
||||
activation=linear
|
||||
|
||||
# 23
|
||||
[yolo]
|
||||
mask = 1,2,3
|
||||
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
|
||||
classes=80
|
||||
num=6
|
||||
jitter=.3
|
||||
ignore_thresh = .7
|
||||
truth_thresh = 1
|
||||
random=1
|
||||
797
config/yolov3.cfg
Normal file
797
config/yolov3.cfg
Normal file
@ -0,0 +1,797 @@
|
||||
[net]
|
||||
# Testing
|
||||
#batch=1
|
||||
#subdivisions=1
|
||||
# Training
|
||||
batch=16
|
||||
subdivisions=1
|
||||
width=416
|
||||
height=416
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation = 1.5
|
||||
exposure = 1.5
|
||||
hue=.1
|
||||
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches = 500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
# Downsample
|
||||
# res1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
# res2
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
# res8
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
# route1
|
||||
|
||||
# Downsample
|
||||
# res8
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
# route2
|
||||
|
||||
# Downsample
|
||||
# res4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
######################
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
# route3
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=255
|
||||
activation=linear
|
||||
|
||||
|
||||
[yolo]
|
||||
mask = 6,7,8
|
||||
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=80
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh = .7
|
||||
truth_thresh = 1
|
||||
random=1
|
||||
|
||||
|
||||
[route]
|
||||
layers = -4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers = -1, 61
|
||||
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
# route
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=255
|
||||
activation=linear
|
||||
|
||||
|
||||
[yolo]
|
||||
mask = 3,4,5
|
||||
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=80
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh = .7
|
||||
truth_thresh = 1
|
||||
random=1
|
||||
|
||||
|
||||
|
||||
[route]
|
||||
layers = -4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers = -1, 36
|
||||
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=255
|
||||
activation=linear
|
||||
|
||||
|
||||
[yolo]
|
||||
mask = 0,1,2
|
||||
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=80
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh = .7
|
||||
truth_thresh = 1
|
||||
random=1
|
||||
4
data/README.md
Normal file
4
data/README.md
Normal file
@ -0,0 +1,4 @@
|
||||
1. 将压缩文件解压到当前目录,得到hand_dataset文件夹
|
||||
2. 在该目录下执行converter.py,生成images、labels文件夹和train.txt、valid.txt文件
|
||||
3. 新建oxfordhand.names文件,记录类别名称信息
|
||||
4. 该目录下有images、labels、converter.py、oxfordhand.names、train.txt、valid.txt、readme.md共7个文件,可以删掉其他文件
|
||||
115
data/converter.py
Normal file
115
data/converter.py
Normal file
@ -0,0 +1,115 @@
|
||||
import scipy.io as sio
|
||||
from PIL import Image
|
||||
import os, glob
|
||||
import datetime
|
||||
import shutil
|
||||
|
||||
running_from_path = os.getcwd()
|
||||
created_images_dir = 'images'
|
||||
created_labels_dir = 'labels'
|
||||
data_dir = 'data' # data_dir为脚本所在的文件夹
|
||||
|
||||
def hms_string(sec_elapsed): # 格式化显示已消耗时间
|
||||
h = int(sec_elapsed / (60 * 60))
|
||||
m = int((sec_elapsed % (60 * 60)) / 60)
|
||||
s = sec_elapsed % 60.
|
||||
return "{}:{:>02}:{:>05.2f}".format(h, m, s)
|
||||
|
||||
def generate_dir(set_name, root_path): # 往images和labels文件夹下生成相应的文件夹
|
||||
images_dir = os.path.join(root_path, 'images')
|
||||
annotation_dir = os.path.join(root_path, 'annotations')
|
||||
|
||||
new_images_dir = os.path.join(created_images_dir, set_name) # 将图片从原来的文件夹复制到该文件夹下
|
||||
new_annotation_dir = os.path.join(created_labels_dir, set_name)
|
||||
|
||||
if not os.path.exists(new_images_dir):
|
||||
os.makedirs(new_images_dir)
|
||||
|
||||
if not os.path.exists(new_annotation_dir):
|
||||
os.makedirs(new_annotation_dir)
|
||||
|
||||
for img in glob.glob(os.path.join(images_dir, "*.jpg")): # 将图片从原来的文件夹复制到新文件夹下
|
||||
shutil.copy(img, new_images_dir)
|
||||
|
||||
os.chdir(annotation_dir) # 切换到annotation的路径下
|
||||
matlab_annotations = glob.glob("*.mat") # 仅仅包含文件名,不包含路径
|
||||
os.chdir(running_from_path) # 切换回原来的路径
|
||||
|
||||
for matfile in matlab_annotations:
|
||||
filename = matfile.split(".")[0]
|
||||
|
||||
pil_image = Image.open(os.path.join(images_dir, filename+".jpg"))
|
||||
|
||||
content = sio.loadmat(os.path.join(annotation_dir, matfile), matlab_compatible=False)
|
||||
|
||||
boxes = content["boxes"]
|
||||
|
||||
width, height = pil_image.size
|
||||
|
||||
with open(os.path.join(new_annotation_dir, filename+".txt"), "w") as hs:
|
||||
for box_idx, box in enumerate(boxes.T):
|
||||
a = box[0][0][0][0]
|
||||
b = box[0][0][0][1]
|
||||
c = box[0][0][0][2]
|
||||
d = box[0][0][0][3]
|
||||
|
||||
aXY = (a[0][1], a[0][0])
|
||||
bXY = (b[0][1], b[0][0])
|
||||
cXY = (c[0][1], c[0][0])
|
||||
dXY = (d[0][1], d[0][0])
|
||||
|
||||
maxX = max(aXY[0], bXY[0], cXY[0], dXY[0])
|
||||
minX = min(aXY[0], bXY[0], cXY[0], dXY[0])
|
||||
maxY = max(aXY[1], bXY[1], cXY[1], dXY[1])
|
||||
minY = min(aXY[1], bXY[1], cXY[1], dXY[1])
|
||||
|
||||
# clip,防止超出边界
|
||||
maxX = min(maxX, width-1)
|
||||
minX = max(minX, 0)
|
||||
maxY = min(maxY, height-1)
|
||||
minY = max(minY, 0)
|
||||
|
||||
# (<absolute_x> / <image_width>)
|
||||
norm_width = (maxX - minX) / width
|
||||
|
||||
# (<absolute_y> / <image_height>)
|
||||
norm_height = (maxY - minY) / height
|
||||
|
||||
center_x, center_y = (maxX + minX) / 2, (maxY + minY) / 2
|
||||
|
||||
norm_center_x = center_x / width
|
||||
norm_center_y = center_y / height
|
||||
|
||||
if box_idx != 0:
|
||||
hs.write("\n")
|
||||
|
||||
hs.write("0 %f %f %f %f" % (norm_center_x, norm_center_y, norm_width, norm_height)) # 0表示类别
|
||||
|
||||
def create_txt(dirlist, filename):
|
||||
with open(filename, "w") as txtfile: # 在data文件夹下生成txt文件
|
||||
imglist = []
|
||||
|
||||
for dir in dirlist: # dir='images/test'
|
||||
imglist.extend(glob.glob(os.path.join(dir, "*.jpg"))) # img='images/test/abc.jpg'
|
||||
|
||||
for idx, img in enumerate(imglist):
|
||||
if idx != 0:
|
||||
txtfile.write("\n")
|
||||
txtfile.write(os.path.join(data_dir, img)) # 加上前缀data
|
||||
|
||||
if __name__ == '__main__':
|
||||
start_time = datetime.datetime.now()
|
||||
|
||||
generate_dir("train", "hand_dataset/training_dataset/training_data") # 第一个参数表示生成的文件夹的名称
|
||||
generate_dir("test", "hand_dataset/test_dataset/test_data")
|
||||
generate_dir("validation", "hand_dataset/validation_dataset/validation_data")
|
||||
|
||||
create_txt((os.path.join(created_images_dir, 'train'), # 将train和validation文件夹下的图片合并成train
|
||||
os.path.join(created_images_dir, 'validation')),
|
||||
'train.txt')
|
||||
create_txt((os.path.join(created_images_dir, 'test'), ),
|
||||
'valid.txt')
|
||||
|
||||
end_time = datetime.datetime.now()
|
||||
seconds_elapsed = (end_time - start_time).total_seconds()
|
||||
print("It took {} to execute this".format(hms_string(seconds_elapsed)))
|
||||
2
data/oxfordhand.names
Normal file
2
data/oxfordhand.names
Normal file
@ -0,0 +1,2 @@
|
||||
hand
|
||||
|
||||
2
data/person.names
Normal file
2
data/person.names
Normal file
@ -0,0 +1,2 @@
|
||||
person
|
||||
|
||||
128
data/smallvalid.txt
Normal file
128
data/smallvalid.txt
Normal file
@ -0,0 +1,128 @@
|
||||
data/images/0006.jpg
|
||||
data/images/0009.jpg
|
||||
data/images/0010.jpg
|
||||
data/images/0022.jpg
|
||||
data/images/0037.jpg
|
||||
data/images/0039.jpg
|
||||
data/images/0040.jpg
|
||||
data/images/0041.jpg
|
||||
data/images/0044.jpg
|
||||
data/images/0053.jpg
|
||||
data/images/0061.jpg
|
||||
data/images/0066.jpg
|
||||
data/images/0072.jpg
|
||||
data/images/0077.jpg
|
||||
data/images/0078.jpg
|
||||
data/images/0080.jpg
|
||||
data/images/0081.jpg
|
||||
data/images/0086.jpg
|
||||
data/images/0089.jpg
|
||||
data/images/0090.jpg
|
||||
data/images/0095.jpg
|
||||
data/images/0109.jpg
|
||||
data/images/0110.jpg
|
||||
data/images/0120.jpg
|
||||
data/images/0122.jpg
|
||||
data/images/0123.jpg
|
||||
data/images/0124.jpg
|
||||
data/images/0125.jpg
|
||||
data/images/0127.jpg
|
||||
data/images/0135.jpg
|
||||
data/images/0137.jpg
|
||||
data/images/0140.jpg
|
||||
data/images/0141.jpg
|
||||
data/images/0146.jpg
|
||||
data/images/0157.jpg
|
||||
data/images/0159.jpg
|
||||
data/images/0162.jpg
|
||||
data/images/0164.jpg
|
||||
data/images/0165.jpg
|
||||
data/images/0169.jpg
|
||||
data/images/0178.jpg
|
||||
data/images/0183.jpg
|
||||
data/images/0189.jpg
|
||||
data/images/0193.jpg
|
||||
data/images/0196.jpg
|
||||
data/images/0198.jpg
|
||||
data/images/0203.jpg
|
||||
data/images/0214.jpg
|
||||
data/images/0218.jpg
|
||||
data/images/0219.jpg
|
||||
data/images/0223.jpg
|
||||
data/images/0229.jpg
|
||||
data/images/0232.jpg
|
||||
data/images/0244.jpg
|
||||
data/images/0248.jpg
|
||||
data/images/0249.jpg
|
||||
data/images/0256.jpg
|
||||
data/images/0262.jpg
|
||||
data/images/0263.jpg
|
||||
data/images/0280.jpg
|
||||
data/images/0289.jpg
|
||||
data/images/0300.jpg
|
||||
data/images/0306.jpg
|
||||
data/images/0309.jpg
|
||||
data/images/0314.jpg
|
||||
data/images/0316.jpg
|
||||
data/images/0320.jpg
|
||||
data/images/0348.jpg
|
||||
data/images/0355.jpg
|
||||
data/images/0361.jpg
|
||||
data/images/0362.jpg
|
||||
data/images/0365.jpg
|
||||
data/images/0368.jpg
|
||||
data/images/0369.jpg
|
||||
data/images/0376.jpg
|
||||
data/images/0383.jpg
|
||||
data/images/0390.jpg
|
||||
data/images/0396.jpg
|
||||
data/images/0399.jpg
|
||||
data/images/0410.jpg
|
||||
data/images/0419.jpg
|
||||
data/images/0421.jpg
|
||||
data/images/0431.jpg
|
||||
data/images/0435.jpg
|
||||
data/images/0437.jpg
|
||||
data/images/0441.jpg
|
||||
data/images/0451.jpg
|
||||
data/images/0456.jpg
|
||||
data/images/0459.jpg
|
||||
data/images/0462.jpg
|
||||
data/images/0469.jpg
|
||||
data/images/0471.jpg
|
||||
data/images/0472.jpg
|
||||
data/images/0479.jpg
|
||||
data/images/0480.jpg
|
||||
data/images/0482.jpg
|
||||
data/images/0487.jpg
|
||||
data/images/0488.jpg
|
||||
data/images/0490.jpg
|
||||
data/images/0494.jpg
|
||||
data/images/0505.jpg
|
||||
data/images/0506.jpg
|
||||
data/images/0510.jpg
|
||||
data/images/0513.jpg
|
||||
data/images/0521.jpg
|
||||
data/images/0522.jpg
|
||||
data/images/0523.jpg
|
||||
data/images/0526.jpg
|
||||
data/images/0529.jpg
|
||||
data/images/0541.jpg
|
||||
data/images/0547.jpg
|
||||
data/images/0548.jpg
|
||||
data/images/0549.jpg
|
||||
data/images/0556.jpg
|
||||
data/images/0564.jpg
|
||||
data/images/0572.jpg
|
||||
data/images/0577.jpg
|
||||
data/images/0578.jpg
|
||||
data/images/0579.jpg
|
||||
data/images/0584.jpg
|
||||
data/images/0586.jpg
|
||||
data/images/0590.jpg
|
||||
data/images/0596.jpg
|
||||
data/images/0598.jpg
|
||||
data/images/0600.jpg
|
||||
data/images/0603.jpg
|
||||
data/images/0606.jpg
|
||||
data/images/0614.jpg
|
||||
7935
data/train.txt
Normal file
7935
data/train.txt
Normal file
File diff suppressed because it is too large
Load Diff
1590
data/train_2000.txt
Normal file
1590
data/train_2000.txt
Normal file
File diff suppressed because it is too large
Load Diff
2065
data/valid.txt
Normal file
2065
data/valid.txt
Normal file
File diff suppressed because it is too large
Load Diff
410
data/valid_2000.txt
Normal file
410
data/valid_2000.txt
Normal file
@ -0,0 +1,410 @@
|
||||
data/images/0006.jpg
|
||||
data/images/0009.jpg
|
||||
data/images/0010.jpg
|
||||
data/images/0022.jpg
|
||||
data/images/0037.jpg
|
||||
data/images/0039.jpg
|
||||
data/images/0040.jpg
|
||||
data/images/0041.jpg
|
||||
data/images/0044.jpg
|
||||
data/images/0053.jpg
|
||||
data/images/0061.jpg
|
||||
data/images/0066.jpg
|
||||
data/images/0072.jpg
|
||||
data/images/0077.jpg
|
||||
data/images/0078.jpg
|
||||
data/images/0080.jpg
|
||||
data/images/0081.jpg
|
||||
data/images/0086.jpg
|
||||
data/images/0089.jpg
|
||||
data/images/0090.jpg
|
||||
data/images/0095.jpg
|
||||
data/images/0109.jpg
|
||||
data/images/0110.jpg
|
||||
data/images/0120.jpg
|
||||
data/images/0122.jpg
|
||||
data/images/0123.jpg
|
||||
data/images/0124.jpg
|
||||
data/images/0125.jpg
|
||||
data/images/0127.jpg
|
||||
data/images/0135.jpg
|
||||
data/images/0137.jpg
|
||||
data/images/0140.jpg
|
||||
data/images/0141.jpg
|
||||
data/images/0146.jpg
|
||||
data/images/0157.jpg
|
||||
data/images/0159.jpg
|
||||
data/images/0162.jpg
|
||||
data/images/0164.jpg
|
||||
data/images/0165.jpg
|
||||
data/images/0169.jpg
|
||||
data/images/0178.jpg
|
||||
data/images/0183.jpg
|
||||
data/images/0189.jpg
|
||||
data/images/0193.jpg
|
||||
data/images/0196.jpg
|
||||
data/images/0198.jpg
|
||||
data/images/0203.jpg
|
||||
data/images/0214.jpg
|
||||
data/images/0218.jpg
|
||||
data/images/0219.jpg
|
||||
data/images/0223.jpg
|
||||
data/images/0229.jpg
|
||||
data/images/0232.jpg
|
||||
data/images/0244.jpg
|
||||
data/images/0248.jpg
|
||||
data/images/0249.jpg
|
||||
data/images/0256.jpg
|
||||
data/images/0262.jpg
|
||||
data/images/0263.jpg
|
||||
data/images/0280.jpg
|
||||
data/images/0289.jpg
|
||||
data/images/0300.jpg
|
||||
data/images/0306.jpg
|
||||
data/images/0309.jpg
|
||||
data/images/0314.jpg
|
||||
data/images/0316.jpg
|
||||
data/images/0320.jpg
|
||||
data/images/0348.jpg
|
||||
data/images/0355.jpg
|
||||
data/images/0361.jpg
|
||||
data/images/0362.jpg
|
||||
data/images/0365.jpg
|
||||
data/images/0368.jpg
|
||||
data/images/0369.jpg
|
||||
data/images/0376.jpg
|
||||
data/images/0383.jpg
|
||||
data/images/0390.jpg
|
||||
data/images/0396.jpg
|
||||
data/images/0399.jpg
|
||||
data/images/0410.jpg
|
||||
data/images/0419.jpg
|
||||
data/images/0421.jpg
|
||||
data/images/0431.jpg
|
||||
data/images/0435.jpg
|
||||
data/images/0437.jpg
|
||||
data/images/0441.jpg
|
||||
data/images/0451.jpg
|
||||
data/images/0456.jpg
|
||||
data/images/0459.jpg
|
||||
data/images/0462.jpg
|
||||
data/images/0469.jpg
|
||||
data/images/0471.jpg
|
||||
data/images/0472.jpg
|
||||
data/images/0479.jpg
|
||||
data/images/0480.jpg
|
||||
data/images/0482.jpg
|
||||
data/images/0487.jpg
|
||||
data/images/0488.jpg
|
||||
data/images/0490.jpg
|
||||
data/images/0494.jpg
|
||||
data/images/0505.jpg
|
||||
data/images/0506.jpg
|
||||
data/images/0510.jpg
|
||||
data/images/0513.jpg
|
||||
data/images/0521.jpg
|
||||
data/images/0522.jpg
|
||||
data/images/0523.jpg
|
||||
data/images/0526.jpg
|
||||
data/images/0529.jpg
|
||||
data/images/0541.jpg
|
||||
data/images/0547.jpg
|
||||
data/images/0548.jpg
|
||||
data/images/0549.jpg
|
||||
data/images/0556.jpg
|
||||
data/images/0564.jpg
|
||||
data/images/0572.jpg
|
||||
data/images/0577.jpg
|
||||
data/images/0578.jpg
|
||||
data/images/0579.jpg
|
||||
data/images/0584.jpg
|
||||
data/images/0586.jpg
|
||||
data/images/0590.jpg
|
||||
data/images/0596.jpg
|
||||
data/images/0598.jpg
|
||||
data/images/0600.jpg
|
||||
data/images/0603.jpg
|
||||
data/images/0606.jpg
|
||||
data/images/0614.jpg
|
||||
data/images/0615.jpg
|
||||
data/images/0618.jpg
|
||||
data/images/0622.jpg
|
||||
data/images/0625.jpg
|
||||
data/images/0627.jpg
|
||||
data/images/0630.jpg
|
||||
data/images/0631.jpg
|
||||
data/images/0634.jpg
|
||||
data/images/0637.jpg
|
||||
data/images/0649.jpg
|
||||
data/images/0650.jpg
|
||||
data/images/0661.jpg
|
||||
data/images/0663.jpg
|
||||
data/images/0671.jpg
|
||||
data/images/0674.jpg
|
||||
data/images/0679.jpg
|
||||
data/images/0684.jpg
|
||||
data/images/0688.jpg
|
||||
data/images/0690.jpg
|
||||
data/images/0696.jpg
|
||||
data/images/0697.jpg
|
||||
data/images/0712.jpg
|
||||
data/images/0718.jpg
|
||||
data/images/0729.jpg
|
||||
data/images/0739.jpg
|
||||
data/images/0746.jpg
|
||||
data/images/0748.jpg
|
||||
data/images/0750.jpg
|
||||
data/images/0753.jpg
|
||||
data/images/0755.jpg
|
||||
data/images/0756.jpg
|
||||
data/images/0765.jpg
|
||||
data/images/0766.jpg
|
||||
data/images/0772.jpg
|
||||
data/images/0779.jpg
|
||||
data/images/0780.jpg
|
||||
data/images/0782.jpg
|
||||
data/images/0785.jpg
|
||||
data/images/0790.jpg
|
||||
data/images/0791.jpg
|
||||
data/images/0797.jpg
|
||||
data/images/0798.jpg
|
||||
data/images/0809.jpg
|
||||
data/images/0814.jpg
|
||||
data/images/0815.jpg
|
||||
data/images/0825.jpg
|
||||
data/images/0827.jpg
|
||||
data/images/0832.jpg
|
||||
data/images/0852.jpg
|
||||
data/images/0857.jpg
|
||||
data/images/0860.jpg
|
||||
data/images/0865.jpg
|
||||
data/images/0866.jpg
|
||||
data/images/0867.jpg
|
||||
data/images/0873.jpg
|
||||
data/images/0880.jpg
|
||||
data/images/0892.jpg
|
||||
data/images/0896.jpg
|
||||
data/images/0917.jpg
|
||||
data/images/0919.jpg
|
||||
data/images/0924.jpg
|
||||
data/images/0925.jpg
|
||||
data/images/0931.jpg
|
||||
data/images/0934.jpg
|
||||
data/images/0935.jpg
|
||||
data/images/0939.jpg
|
||||
data/images/0945.jpg
|
||||
data/images/0954.jpg
|
||||
data/images/0961.jpg
|
||||
data/images/0966.jpg
|
||||
data/images/0968.jpg
|
||||
data/images/0975.jpg
|
||||
data/images/0976.jpg
|
||||
data/images/0984.jpg
|
||||
data/images/0993.jpg
|
||||
data/images/1003.jpg
|
||||
data/images/1015.jpg
|
||||
data/images/1017.jpg
|
||||
data/images/1018.jpg
|
||||
data/images/1020.jpg
|
||||
data/images/1025.jpg
|
||||
data/images/1027.jpg
|
||||
data/images/1031.jpg
|
||||
data/images/1039.jpg
|
||||
data/images/1041.jpg
|
||||
data/images/1046.jpg
|
||||
data/images/1050.jpg
|
||||
data/images/1056.jpg
|
||||
data/images/1067.jpg
|
||||
data/images/1069.jpg
|
||||
data/images/1071.jpg
|
||||
data/images/1074.jpg
|
||||
data/images/1077.jpg
|
||||
data/images/1083.jpg
|
||||
data/images/1089.jpg
|
||||
data/images/1093.jpg
|
||||
data/images/1095.jpg
|
||||
data/images/1101.jpg
|
||||
data/images/1102.jpg
|
||||
data/images/1105.jpg
|
||||
data/images/1112.jpg
|
||||
data/images/1120.jpg
|
||||
data/images/1124.jpg
|
||||
data/images/1126.jpg
|
||||
data/images/1127.jpg
|
||||
data/images/1129.jpg
|
||||
data/images/1142.jpg
|
||||
data/images/1145.jpg
|
||||
data/images/1149.jpg
|
||||
data/images/1152.jpg
|
||||
data/images/1154.jpg
|
||||
data/images/1157.jpg
|
||||
data/images/1161.jpg
|
||||
data/images/1165.jpg
|
||||
data/images/1166.jpg
|
||||
data/images/1167.jpg
|
||||
data/images/1178.jpg
|
||||
data/images/1179.jpg
|
||||
data/images/1185.jpg
|
||||
data/images/1187.jpg
|
||||
data/images/1189.jpg
|
||||
data/images/1191.jpg
|
||||
data/images/1207.jpg
|
||||
data/images/1208.jpg
|
||||
data/images/1209.jpg
|
||||
data/images/1217.jpg
|
||||
data/images/1218.jpg
|
||||
data/images/1220.jpg
|
||||
data/images/1222.jpg
|
||||
data/images/1227.jpg
|
||||
data/images/1231.jpg
|
||||
data/images/1232.jpg
|
||||
data/images/1236.jpg
|
||||
data/images/1245.jpg
|
||||
data/images/1256.jpg
|
||||
data/images/1273.jpg
|
||||
data/images/1276.jpg
|
||||
data/images/1282.jpg
|
||||
data/images/1290.jpg
|
||||
data/images/1293.jpg
|
||||
data/images/1295.jpg
|
||||
data/images/1297.jpg
|
||||
data/images/1299.jpg
|
||||
data/images/1305.jpg
|
||||
data/images/1315.jpg
|
||||
data/images/1317.jpg
|
||||
data/images/1319.jpg
|
||||
data/images/1336.jpg
|
||||
data/images/1337.jpg
|
||||
data/images/1343.jpg
|
||||
data/images/1344.jpg
|
||||
data/images/1347.jpg
|
||||
data/images/1356.jpg
|
||||
data/images/1362.jpg
|
||||
data/images/1365.jpg
|
||||
data/images/1370.jpg
|
||||
data/images/1372.jpg
|
||||
data/images/1375.jpg
|
||||
data/images/1378.jpg
|
||||
data/images/1383.jpg
|
||||
data/images/1385.jpg
|
||||
data/images/1393.jpg
|
||||
data/images/1398.jpg
|
||||
data/images/1400.jpg
|
||||
data/images/1401.jpg
|
||||
data/images/1409.jpg
|
||||
data/images/1415.jpg
|
||||
data/images/1417.jpg
|
||||
data/images/1419.jpg
|
||||
data/images/1422.jpg
|
||||
data/images/1425.jpg
|
||||
data/images/1429.jpg
|
||||
data/images/1441.jpg
|
||||
data/images/1443.jpg
|
||||
data/images/1448.jpg
|
||||
data/images/1450.jpg
|
||||
data/images/1454.jpg
|
||||
data/images/1457.jpg
|
||||
data/images/1459.jpg
|
||||
data/images/1465.jpg
|
||||
data/images/1466.jpg
|
||||
data/images/1470.jpg
|
||||
data/images/1480.jpg
|
||||
data/images/1481.jpg
|
||||
data/images/1483.jpg
|
||||
data/images/1485.jpg
|
||||
data/images/1486.jpg
|
||||
data/images/1488.jpg
|
||||
data/images/1489.jpg
|
||||
data/images/1491.jpg
|
||||
data/images/1495.jpg
|
||||
data/images/1499.jpg
|
||||
data/images/1501.jpg
|
||||
data/images/1502.jpg
|
||||
data/images/1509.jpg
|
||||
data/images/1527.jpg
|
||||
data/images/1530.jpg
|
||||
data/images/1535.jpg
|
||||
data/images/1537.jpg
|
||||
data/images/1548.jpg
|
||||
data/images/1552.jpg
|
||||
data/images/1572.jpg
|
||||
data/images/1575.jpg
|
||||
data/images/1591.jpg
|
||||
data/images/1596.jpg
|
||||
data/images/1597.jpg
|
||||
data/images/1600.jpg
|
||||
data/images/1605.jpg
|
||||
data/images/1609.jpg
|
||||
data/images/1622.jpg
|
||||
data/images/1624.jpg
|
||||
data/images/1635.jpg
|
||||
data/images/1637.jpg
|
||||
data/images/1640.jpg
|
||||
data/images/1646.jpg
|
||||
data/images/1651.jpg
|
||||
data/images/1657.jpg
|
||||
data/images/1660.jpg
|
||||
data/images/1666.jpg
|
||||
data/images/1676.jpg
|
||||
data/images/1679.jpg
|
||||
data/images/1681.jpg
|
||||
data/images/1684.jpg
|
||||
data/images/1688.jpg
|
||||
data/images/1691.jpg
|
||||
data/images/1694.jpg
|
||||
data/images/1695.jpg
|
||||
data/images/1696.jpg
|
||||
data/images/1699.jpg
|
||||
data/images/1706.jpg
|
||||
data/images/1712.jpg
|
||||
data/images/1721.jpg
|
||||
data/images/1722.jpg
|
||||
data/images/1734.jpg
|
||||
data/images/1736.jpg
|
||||
data/images/1737.jpg
|
||||
data/images/1739.jpg
|
||||
data/images/1740.jpg
|
||||
data/images/1749.jpg
|
||||
data/images/1758.jpg
|
||||
data/images/1759.jpg
|
||||
data/images/1770.jpg
|
||||
data/images/1772.jpg
|
||||
data/images/1777.jpg
|
||||
data/images/1778.jpg
|
||||
data/images/1783.jpg
|
||||
data/images/1784.jpg
|
||||
data/images/1787.jpg
|
||||
data/images/1798.jpg
|
||||
data/images/1799.jpg
|
||||
data/images/1803.jpg
|
||||
data/images/1805.jpg
|
||||
data/images/1818.jpg
|
||||
data/images/1829.jpg
|
||||
data/images/1830.jpg
|
||||
data/images/1834.jpg
|
||||
data/images/1837.jpg
|
||||
data/images/1857.jpg
|
||||
data/images/1863.jpg
|
||||
data/images/1864.jpg
|
||||
data/images/1886.jpg
|
||||
data/images/1890.jpg
|
||||
data/images/1904.jpg
|
||||
data/images/1909.jpg
|
||||
data/images/1922.jpg
|
||||
data/images/1923.jpg
|
||||
data/images/1924.jpg
|
||||
data/images/1925.jpg
|
||||
data/images/1928.jpg
|
||||
data/images/1933.jpg
|
||||
data/images/1936.jpg
|
||||
data/images/1939.jpg
|
||||
data/images/1950.jpg
|
||||
data/images/1952.jpg
|
||||
data/images/1956.jpg
|
||||
data/images/1965.jpg
|
||||
data/images/1968.jpg
|
||||
data/images/1971.jpg
|
||||
data/images/1986.jpg
|
||||
data/images/1988.jpg
|
||||
data/images/1995.jpg
|
||||
data/images/1996.jpg
|
||||
21
debug_utils.py
Normal file
21
debug_utils.py
Normal file
@ -0,0 +1,21 @@
|
||||
def inspect_lr(optimizer):
|
||||
cur_lr = optimizer.param_groups[0]['lr']
|
||||
print('Current learning rate: %0.6f' % cur_lr)
|
||||
return cur_lr
|
||||
|
||||
# 将学习率衰减为原来的gamma倍数
|
||||
def modify_lr(optimizer, gamma):
|
||||
cur_lr = inspect_lr(optimizer)
|
||||
new_lr = cur_lr * gamma
|
||||
print('Learning rate has been changed from %0.6f to %0.6f' % (cur_lr, new_lr))
|
||||
for group in optimizer.param_groups:
|
||||
group['lr'] = new_lr
|
||||
return new_lr
|
||||
|
||||
def turn_on_sr(opt):
|
||||
opt.sr = True
|
||||
print('Sr has been turned on!')
|
||||
|
||||
def turn_off_sr(opt):
|
||||
opt.sr = False
|
||||
print('Sr has been turned off!')
|
||||
410
models.py
Normal file
410
models.py
Normal file
@ -0,0 +1,410 @@
|
||||
from __future__ import division
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from torch.autograd import Variable
|
||||
import numpy as np
|
||||
|
||||
from utils.parse_config import *
|
||||
from utils.utils import build_targets, to_cpu, non_max_suppression
|
||||
|
||||
import matplotlib.pyplot as plt
|
||||
import matplotlib.patches as patches
|
||||
|
||||
# convolutional,maxpool,upsample,route,shortcut,yolo
|
||||
|
||||
def create_modules(module_defs):
|
||||
"""
|
||||
Constructs module list of layer blocks from module configuration in module_defs
|
||||
"""
|
||||
hyperparams = module_defs.pop(0)
|
||||
output_filters = [int(hyperparams["channels"])]
|
||||
module_list = nn.ModuleList() # 一定要用ModuleList()才能被torch识别为module并进行管理,不能用list!
|
||||
for module_i, module_def in enumerate(module_defs):
|
||||
modules = nn.Sequential()
|
||||
|
||||
if module_def["type"] == "convolutional":
|
||||
bn = int(module_def["batch_normalize"])
|
||||
filters = int(module_def["filters"])
|
||||
kernel_size = int(module_def["size"])
|
||||
pad = (kernel_size - 1) // 2
|
||||
modules.add_module(
|
||||
f"conv_{module_i}",
|
||||
nn.Conv2d(
|
||||
in_channels=output_filters[-1],
|
||||
out_channels=filters,
|
||||
kernel_size=kernel_size,
|
||||
stride=int(module_def["stride"]),
|
||||
padding=pad,
|
||||
bias=not bn,
|
||||
),
|
||||
)
|
||||
if bn:
|
||||
# modules.add_module(f"batch_norm_{module_i}", nn.BatchNorm2d(filters, momentum=0.9, eps=1e-5))
|
||||
modules.add_module(f"batch_norm_{module_i}", nn.BatchNorm2d(filters))
|
||||
if module_def["activation"] == "leaky":
|
||||
modules.add_module(f"leaky_{module_i}", nn.LeakyReLU(0.1, inplace=True))
|
||||
|
||||
# 增加了深度可分离卷积
|
||||
elif module_def["type"] == "ds_conv":
|
||||
bn = int(module_def["batch_normalize"])
|
||||
filters = int(module_def["filters"])
|
||||
kernel_size = int(module_def["size"])
|
||||
pad = int(module_def["pad"])
|
||||
# 逐通道
|
||||
modules.add_module(
|
||||
f"ds_conv_d_{module_i}",
|
||||
nn.Conv2d(
|
||||
in_channels=output_filters[-1],
|
||||
out_channels=output_filters[-1],
|
||||
kernel_size=kernel_size,
|
||||
stride=int(module_def["stride"]),
|
||||
padding=pad,
|
||||
groups=output_filters[-1], # 和in_channels相同
|
||||
),
|
||||
)
|
||||
# 逐点
|
||||
modules.add_module(
|
||||
f"ds_conv_p_{module_i}",
|
||||
nn.Conv2d(
|
||||
in_channels=output_filters[-1],
|
||||
out_channels=filters,
|
||||
kernel_size=1,
|
||||
stride=1,
|
||||
padding=0,
|
||||
groups=1,
|
||||
),
|
||||
)
|
||||
|
||||
if bn:
|
||||
# modules.add_module(f"batch_norm_{module_i}", nn.BatchNorm2d(filters, momentum=0.9, eps=1e-5))
|
||||
modules.add_module(f"batch_norm_{module_i}", nn.BatchNorm2d(filters))
|
||||
if module_def["activation"] == "leaky":
|
||||
modules.add_module(f"leaky_{module_i}", nn.LeakyReLU(0.1, inplace=True))
|
||||
|
||||
|
||||
elif module_def["type"] == "maxpool":
|
||||
kernel_size = int(module_def["size"])
|
||||
stride = int(module_def["stride"])
|
||||
if kernel_size == 2 and stride == 1:
|
||||
modules.add_module(f"_debug_padding_{module_i}", nn.ZeroPad2d((0, 1, 0, 1)))
|
||||
maxpool = nn.MaxPool2d(kernel_size=kernel_size, stride=stride, padding=int((kernel_size - 1) // 2))
|
||||
modules.add_module(f"maxpool_{module_i}", maxpool)
|
||||
|
||||
elif module_def["type"] == "upsample":
|
||||
upsample = Upsample(scale_factor=int(module_def["stride"]), mode="nearest")
|
||||
modules.add_module(f"upsample_{module_i}", upsample)
|
||||
|
||||
elif module_def["type"] == "route": #路由层进行拼接操作 比如: 输入1:26*26*256 输入2: 26*26*128 输出: 26*26*(256+128)
|
||||
layers = [int(x) for x in module_def["layers"].split(",")]
|
||||
filters = sum([output_filters[1:][i] for i in layers])
|
||||
modules.add_module(f"route_{module_i}", EmptyLayer())
|
||||
|
||||
elif module_def["type"] == "shortcut": #残差连接,并不是通道拼接,而是每个通道的特征图逐元素相加,并不会改变通道数量
|
||||
filters = output_filters[1:][int(module_def["from"])]
|
||||
modules.add_module(f"shortcut_{module_i}", EmptyLayer())
|
||||
|
||||
elif module_def["type"] == "yolo":
|
||||
anchor_idxs = [int(x) for x in module_def["mask"].split(",")]
|
||||
# Extract anchors
|
||||
anchors = [int(x) for x in module_def["anchors"].split(",")]
|
||||
anchors = [(anchors[i], anchors[i + 1]) for i in range(0, len(anchors), 2)]
|
||||
anchors = [anchors[i] for i in anchor_idxs]
|
||||
num_classes = int(module_def["classes"])
|
||||
img_size = int(hyperparams["height"])
|
||||
# Define detection layer
|
||||
yolo_layer = YOLOLayer(anchors, num_classes, img_size)
|
||||
modules.add_module(f"yolo_{module_i}", yolo_layer)
|
||||
# Register module list and number of output filters
|
||||
module_list.append(modules)
|
||||
output_filters.append(filters) # filter保存了输出的维度
|
||||
|
||||
return hyperparams, module_list
|
||||
|
||||
|
||||
class Upsample(nn.Module):
|
||||
""" nn.Upsample is deprecated """
|
||||
|
||||
def __init__(self, scale_factor, mode="nearest"):
|
||||
super(Upsample, self).__init__()
|
||||
self.scale_factor = scale_factor
|
||||
self.mode = mode
|
||||
|
||||
def forward(self, x):
|
||||
x = F.interpolate(x, scale_factor=self.scale_factor, mode=self.mode)
|
||||
return x
|
||||
|
||||
|
||||
class EmptyLayer(nn.Module): # 只是为了占位,以便处理route层和shortcut层
|
||||
"""Placeholder for 'route' and 'shortcut' layers"""
|
||||
|
||||
def __init__(self):
|
||||
super(EmptyLayer, self).__init__()
|
||||
|
||||
|
||||
class YOLOLayer(nn.Module):
|
||||
"""Detection layer"""
|
||||
|
||||
def __init__(self, anchors, num_classes, img_dim=416):
|
||||
super(YOLOLayer, self).__init__()
|
||||
self.anchors = anchors
|
||||
self.num_anchors = len(anchors)
|
||||
self.num_classes = num_classes
|
||||
self.ignore_thres = 0.5
|
||||
self.mse_loss = nn.MSELoss()
|
||||
self.bce_loss = nn.BCELoss()
|
||||
self.obj_scale = 1
|
||||
self.noobj_scale = 100
|
||||
self.metrics = {}
|
||||
self.img_dim = img_dim
|
||||
self.grid_size = 0 # grid size
|
||||
|
||||
def compute_grid_offsets(self, grid_size, cuda=True):
|
||||
self.grid_size = grid_size
|
||||
g = self.grid_size
|
||||
FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
|
||||
self.stride = self.img_dim / self.grid_size
|
||||
# Calculate offsets for each grid
|
||||
self.grid_x = torch.arange(g).repeat(g, 1).view([1, 1, g, g]).type(FloatTensor)
|
||||
self.grid_y = torch.arange(g).repeat(g, 1).t().view([1, 1, g, g]).type(FloatTensor)
|
||||
self.scaled_anchors = FloatTensor([(a_w / self.stride, a_h / self.stride) for a_w, a_h in self.anchors])
|
||||
self.anchor_w = self.scaled_anchors[:, 0:1].view((1, self.num_anchors, 1, 1)) # anchor_w的范围是[0, grid_size](416下),浮点型数值
|
||||
self.anchor_h = self.scaled_anchors[:, 1:2].view((1, self.num_anchors, 1, 1))
|
||||
|
||||
def forward(self, x, targets=None, img_dim=None):
|
||||
|
||||
# Tensors for cuda support
|
||||
FloatTensor = torch.cuda.FloatTensor if x.is_cuda else torch.FloatTensor
|
||||
LongTensor = torch.cuda.LongTensor if x.is_cuda else torch.LongTensor
|
||||
ByteTensor = torch.cuda.ByteTensor if x.is_cuda else torch.ByteTensor
|
||||
|
||||
self.img_dim = img_dim
|
||||
num_samples = x.size(0)
|
||||
grid_size = x.size(2)
|
||||
|
||||
prediction = (
|
||||
x.view(num_samples, self.num_anchors, self.num_classes + 5, grid_size, grid_size)
|
||||
.permute(0, 1, 3, 4, 2) # num_samples, num_anchors, grid_size, grid_size, self.num_classes + 5
|
||||
.contiguous()
|
||||
)
|
||||
|
||||
# Get outputs
|
||||
x = torch.sigmoid(prediction[..., 0]) # Center x
|
||||
y = torch.sigmoid(prediction[..., 1]) # Center y
|
||||
w = prediction[..., 2] # Width
|
||||
h = prediction[..., 3] # Height
|
||||
pred_conf = torch.sigmoid(prediction[..., 4]) # Conf
|
||||
pred_cls = torch.sigmoid(prediction[..., 5:]) # Cls pred.
|
||||
|
||||
# If grid size does not match current we compute new offsets
|
||||
if grid_size != self.grid_size: # 不用每次都计算,只有在输入图片大小第一次发生变化时计算
|
||||
self.compute_grid_offsets(grid_size, cuda=x.is_cuda)
|
||||
|
||||
# Add offset and scale with anchors
|
||||
pred_boxes = FloatTensor(prediction[..., :4].shape) # 生成形状与prediction[..., :4]相同的张量
|
||||
pred_boxes[..., 0] = x.data + self.grid_x
|
||||
pred_boxes[..., 1] = y.data + self.grid_y
|
||||
pred_boxes[..., 2] = torch.exp(w.data) * self.anchor_w # anchor_w的范围是[0,grid_size](416下),浮点型变量
|
||||
pred_boxes[..., 3] = torch.exp(h.data) * self.anchor_h
|
||||
|
||||
output = torch.cat(
|
||||
(
|
||||
pred_boxes.view(num_samples, -1, 4) * self.stride,
|
||||
pred_conf.view(num_samples, -1, 1),
|
||||
pred_cls.view(num_samples, -1, self.num_classes), # num_samples, num_anchors*grid_size*grid_size, 85
|
||||
),
|
||||
-1,
|
||||
)
|
||||
|
||||
if targets is None:
|
||||
return output, 0
|
||||
else:
|
||||
iou_scores, class_mask, obj_mask, noobj_mask, tx, ty, tw, th, tcls, tconf = build_targets(
|
||||
pred_boxes=pred_boxes,
|
||||
pred_cls=pred_cls,
|
||||
target=targets,
|
||||
anchors=self.scaled_anchors,
|
||||
ignore_thres=self.ignore_thres,
|
||||
)
|
||||
|
||||
obj_mask = obj_mask.bool() #将int8转换为bool
|
||||
noobj_mask = noobj_mask.bool() #将int8转换为bool
|
||||
|
||||
# Loss : Mask outputs to ignore non-existing objects (except with conf. loss)
|
||||
# TODO:这里没有针对wh的损失进行加权处理
|
||||
loss_x = self.mse_loss(x[obj_mask], tx[obj_mask])
|
||||
loss_y = self.mse_loss(y[obj_mask], ty[obj_mask])
|
||||
loss_w = self.mse_loss(w[obj_mask], tw[obj_mask])
|
||||
loss_h = self.mse_loss(h[obj_mask], th[obj_mask])
|
||||
loss_conf_obj = self.bce_loss(pred_conf[obj_mask], tconf[obj_mask])
|
||||
loss_conf_noobj = self.bce_loss(pred_conf[noobj_mask], tconf[noobj_mask])
|
||||
loss_conf = self.obj_scale * loss_conf_obj + self.noobj_scale * loss_conf_noobj
|
||||
loss_cls = self.bce_loss(pred_cls[obj_mask], tcls[obj_mask])
|
||||
total_loss = loss_x + loss_y + loss_w + loss_h + loss_conf + loss_cls
|
||||
|
||||
# Metrics
|
||||
cls_acc = 100 * class_mask[obj_mask].mean()
|
||||
conf_obj = pred_conf[obj_mask].mean()
|
||||
conf_noobj = pred_conf[noobj_mask].mean()
|
||||
conf50 = (pred_conf > 0.5).float()
|
||||
iou50 = (iou_scores > 0.5).float()
|
||||
iou75 = (iou_scores > 0.75).float()
|
||||
detected_mask = conf50 * class_mask * tconf
|
||||
precision = torch.sum(iou50 * detected_mask) / (conf50.sum() + 1e-16)
|
||||
recall50 = torch.sum(iou50 * detected_mask) / (obj_mask.sum() + 1e-16)
|
||||
recall75 = torch.sum(iou75 * detected_mask) / (obj_mask.sum() + 1e-16)
|
||||
|
||||
self.metrics = {
|
||||
"loss": to_cpu(total_loss).item(),
|
||||
"x": to_cpu(loss_x).item(),
|
||||
"y": to_cpu(loss_y).item(),
|
||||
"w": to_cpu(loss_w).item(),
|
||||
"h": to_cpu(loss_h).item(),
|
||||
"conf": to_cpu(loss_conf).item(),
|
||||
"cls": to_cpu(loss_cls).item(),
|
||||
"cls_acc": to_cpu(cls_acc).item(),
|
||||
"recall50": to_cpu(recall50).item(),
|
||||
"recall75": to_cpu(recall75).item(),
|
||||
"precision": to_cpu(precision).item(),
|
||||
"conf_obj": to_cpu(conf_obj).item(),
|
||||
"conf_noobj": to_cpu(conf_noobj).item(),
|
||||
"grid_size": grid_size,
|
||||
}
|
||||
|
||||
return output, total_loss
|
||||
|
||||
|
||||
class Darknet(nn.Module):
|
||||
"""YOLOv3 object detection model"""
|
||||
|
||||
def __init__(self, config_path, img_size=416):
|
||||
super(Darknet, self).__init__()
|
||||
|
||||
if isinstance(config_path, str): #读取配置文件
|
||||
self.module_defs = parse_model_config(config_path)
|
||||
elif isinstance(config_path, list):
|
||||
self.module_defs = config_path
|
||||
|
||||
self.hyperparams, self.module_list = create_modules(self.module_defs) #创建模型
|
||||
self.yolo_layers = [layer[0] for layer in self.module_list if hasattr(layer[0], "metrics")] # layer是个nn.Sequential()
|
||||
self.img_size = img_size
|
||||
self.seen = 0
|
||||
self.header_info = np.array([0, 0, 0, self.seen, 0], dtype=np.int32)
|
||||
|
||||
def forward(self, x, targets=None):
|
||||
img_dim = x.shape[2] # 取决于输入图片的大小,因为是正方形输入,所以只考虑height
|
||||
loss = 0
|
||||
layer_outputs, yolo_outputs = [], []
|
||||
for i, (module_def, module) in enumerate(zip(self.module_defs, self.module_list)):
|
||||
if module_def["type"] in ["convolutional", "upsample", "maxpool", "ds_conv"]: # 增加了"ds_conv"
|
||||
x = module(x)
|
||||
elif module_def["type"] == "route":
|
||||
x = torch.cat([layer_outputs[int(layer_i)] for layer_i in module_def["layers"].split(",")], 1)
|
||||
elif module_def["type"] == "shortcut":
|
||||
layer_i = int(module_def["from"])
|
||||
# print(f'{layer_i}' + ':' + str(len(layer_outputs[layer_i])))
|
||||
# print(f'{layer_i}' + '-layer_outputs:' + str(len(layer_outputs[-1])))
|
||||
x = layer_outputs[-1] + layer_outputs[layer_i]
|
||||
elif module_def["type"] == "yolo": # [82, 94, 106] for yolov3
|
||||
x, layer_loss = module[0](x, targets, img_dim) # module是nn.Sequential(),所以要取[0]
|
||||
loss += layer_loss
|
||||
yolo_outputs.append(x)
|
||||
layer_outputs.append(x) # 将每个块的output都保存起来
|
||||
yolo_outputs = to_cpu(torch.cat(yolo_outputs, 1)) # 只保存yolo层的output
|
||||
return yolo_outputs if targets is None else (loss, yolo_outputs)
|
||||
|
||||
def load_darknet_weights(self, weights_path):
|
||||
"""Parses and loads the weights stored in 'weights_path'"""
|
||||
|
||||
# Open the weights file
|
||||
with open(weights_path, "rb") as f:
|
||||
header = np.fromfile(f, dtype=np.int32, count=5) # First five are header values
|
||||
self.header_info = header # Needed to write header when saving weights
|
||||
self.seen = header[3] # number of images seen during training
|
||||
weights = np.fromfile(f, dtype=np.float32) # The rest are weights
|
||||
|
||||
# Establish cutoff for loading backbone weights
|
||||
cutoff = None
|
||||
if "darknet53.conv.74" in weights_path:
|
||||
cutoff = 75
|
||||
|
||||
ptr = 0
|
||||
for i, (module_def, module) in enumerate(zip(self.module_defs, self.module_list)):
|
||||
if i == cutoff:
|
||||
break
|
||||
if module_def["type"] == "convolutional":
|
||||
conv_layer = module[0]
|
||||
if module_def["batch_normalize"]:
|
||||
# Load BN bias, weights, running mean and running variance
|
||||
bn_layer = module[1]
|
||||
num_b = bn_layer.bias.numel() # Number of biases
|
||||
# Bias
|
||||
bn_b = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(bn_layer.bias)
|
||||
bn_layer.bias.data.copy_(bn_b)
|
||||
ptr += num_b
|
||||
# Weight
|
||||
bn_w = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(bn_layer.weight)
|
||||
bn_layer.weight.data.copy_(bn_w)
|
||||
ptr += num_b
|
||||
# Running Mean
|
||||
bn_rm = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(bn_layer.running_mean)
|
||||
bn_layer.running_mean.data.copy_(bn_rm)
|
||||
ptr += num_b
|
||||
# Running Var
|
||||
bn_rv = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(bn_layer.running_var)
|
||||
bn_layer.running_var.data.copy_(bn_rv)
|
||||
ptr += num_b
|
||||
# Load conv. weights
|
||||
num_w = conv_layer.weight.numel()
|
||||
conv_w = torch.from_numpy(weights[ptr: ptr + num_w]).view_as(conv_layer.weight)
|
||||
conv_layer.weight.data.copy_(conv_w)
|
||||
ptr += num_w
|
||||
else:
|
||||
# 对于yolov3.weights,不带bn的卷积层就是YOLO前的卷积层
|
||||
if "yolov3.weights" in weights_path:
|
||||
num_b = 255
|
||||
ptr += num_b
|
||||
num_w = int(self.module_defs[i-1]["filters"]) * 255
|
||||
ptr += num_w
|
||||
else:
|
||||
# Load conv. bias
|
||||
num_b = conv_layer.bias.numel()
|
||||
conv_b = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(conv_layer.bias)
|
||||
conv_layer.bias.data.copy_(conv_b)
|
||||
ptr += num_b
|
||||
# Load conv. weights
|
||||
num_w = conv_layer.weight.numel()
|
||||
conv_w = torch.from_numpy(weights[ptr : ptr + num_w]).view_as(conv_layer.weight)
|
||||
conv_layer.weight.data.copy_(conv_w)
|
||||
ptr += num_w
|
||||
# 确保指针到达权重的最后一个位置
|
||||
assert ptr == len(weights)
|
||||
|
||||
def save_darknet_weights(self, path, cutoff=-1):
|
||||
"""
|
||||
@:param path - path of the new weights file
|
||||
@:param cutoff - save layers between 0 and cutoff (cutoff = -1 -> all are saved)
|
||||
"""
|
||||
fp = open(path, "wb")
|
||||
self.header_info[3] = self.seen
|
||||
self.header_info.tofile(fp)
|
||||
|
||||
# Iterate through layers
|
||||
for i, (module_def, module) in enumerate(zip(self.module_defs[:cutoff], self.module_list[:cutoff])):
|
||||
if module_def["type"] == "convolutional":
|
||||
conv_layer = module[0]
|
||||
# If batch norm, load bn first
|
||||
if module_def["batch_normalize"]:
|
||||
bn_layer = module[1]
|
||||
bn_layer.bias.data.cpu().numpy().tofile(fp)
|
||||
bn_layer.weight.data.cpu().numpy().tofile(fp)
|
||||
bn_layer.running_mean.data.cpu().numpy().tofile(fp)
|
||||
bn_layer.running_var.data.cpu().numpy().tofile(fp)
|
||||
# Load conv bias
|
||||
else:
|
||||
conv_layer.bias.data.cpu().numpy().tofile(fp)
|
||||
# Load conv weights
|
||||
conv_layer.weight.data.cpu().numpy().tofile(fp)
|
||||
|
||||
fp.close()
|
||||
116
test.py
Normal file
116
test.py
Normal file
@ -0,0 +1,116 @@
|
||||
from __future__ import division
|
||||
|
||||
from models import *
|
||||
from utils.utils import *
|
||||
from utils.datasets import *
|
||||
from utils.parse_config import *
|
||||
|
||||
import os
|
||||
import sys
|
||||
import time
|
||||
import datetime
|
||||
import argparse
|
||||
import tqdm
|
||||
|
||||
import torch
|
||||
from torch.utils.data import DataLoader
|
||||
from torchvision import datasets
|
||||
from torchvision import transforms
|
||||
from torch.autograd import Variable
|
||||
import torch.optim as optim
|
||||
import time
|
||||
|
||||
|
||||
def evaluate(model, path, iou_thres, conf_thres, nms_thres, img_size, batch_size):
|
||||
model.eval()
|
||||
|
||||
# Get dataloader
|
||||
dataset = ListDataset(path, img_size=img_size, augment=False, multiscale=False)
|
||||
dataloader = torch.utils.data.DataLoader(
|
||||
dataset, batch_size=batch_size, shuffle=False, num_workers=1, collate_fn=dataset.collate_fn
|
||||
)
|
||||
|
||||
Tensor = torch.cuda.FloatTensor if torch.cuda.is_available() else torch.FloatTensor
|
||||
|
||||
labels = []
|
||||
sample_metrics = [] # List of tuples (TP, confs, pred)
|
||||
for batch_i, (_, imgs, targets) in enumerate(tqdm.tqdm(dataloader, desc="Detecting objects")):
|
||||
|
||||
# Extract labels
|
||||
labels += targets[:, 1].tolist()
|
||||
# Rescale target
|
||||
targets[:, 2:] = xywh2xyxy(targets[:, 2:])
|
||||
targets[:, 2:] *= img_size
|
||||
|
||||
imgs = dataset.resize_imgs(imgs)
|
||||
imgs = Variable(imgs.type(Tensor), requires_grad=False)
|
||||
|
||||
with torch.no_grad():
|
||||
outputs = model(imgs)
|
||||
outputs = non_max_suppression(outputs, conf_thres=conf_thres, nms_thres=nms_thres)
|
||||
|
||||
sample_metrics += get_batch_statistics(outputs, targets, iou_threshold=iou_thres)
|
||||
|
||||
# Concatenate sample statistics
|
||||
assert sample_metrics != []
|
||||
true_positives, pred_scores, pred_labels = [np.concatenate(x, 0) for x in list(zip(*sample_metrics))]
|
||||
precision, recall, AP, f1, ap_class = ap_per_class(true_positives, pred_scores, pred_labels, labels)
|
||||
|
||||
return precision, recall, AP, f1, ap_class
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--batch_size", type=int, default=8, help="size of each image batch")
|
||||
parser.add_argument("--model_def", type=str, default="config/yolov3.cfg", help="path to model definition file")
|
||||
parser.add_argument("--data_config", type=str, default="config/coco.data", help="path to data config file")
|
||||
parser.add_argument("--weights_path", type=str, default="weights/yolov3.weights", help="path to weights file")
|
||||
parser.add_argument("--class_path", type=str, default="data/coco.names", help="path to class label file")
|
||||
parser.add_argument("--iou_thres", type=float, default=0.5, help="iou threshold required to qualify as detected")
|
||||
parser.add_argument("--conf_thres", type=float, default=0.001, help="object confidence threshold")
|
||||
parser.add_argument("--nms_thres", type=float, default=0.5, help="iou thresshold for non-maximum suppression")
|
||||
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
|
||||
parser.add_argument("--img_size", type=int, default=416, help="size of each image dimension")
|
||||
opt = parser.parse_args()
|
||||
print(opt)
|
||||
|
||||
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
||||
|
||||
data_config = parse_data_config(opt.data_config)
|
||||
valid_path = data_config["valid"]
|
||||
class_names = load_classes(data_config["names"])
|
||||
|
||||
# Initiate model
|
||||
model = Darknet(opt.model_def).to(device)
|
||||
if opt.weights_path.endswith(".weights"):
|
||||
# Load darknet weights
|
||||
model.load_darknet_weights(opt.weights_path)
|
||||
else:
|
||||
# Load checkpoint weights
|
||||
model.load_state_dict(torch.load(opt.weights_path))
|
||||
|
||||
print("Compute mAP...")
|
||||
|
||||
precision, recall, AP, f1, ap_class = evaluate(
|
||||
model,
|
||||
path=valid_path,
|
||||
iou_thres=opt.iou_thres,
|
||||
conf_thres=opt.conf_thres,
|
||||
nms_thres=opt.nms_thres,
|
||||
img_size=opt.img_size,
|
||||
batch_size=8,
|
||||
)
|
||||
|
||||
obtain_num_parameters = lambda model:sum([param.nelement() for param in model.parameters()])
|
||||
parameters = obtain_num_parameters(model)
|
||||
print("Parameters : ", f"{parameters}")
|
||||
|
||||
print("Average Precisions:")
|
||||
for i, c in enumerate(ap_class):
|
||||
print(f"+ Class '{c}' ({class_names[c]}) - AP: {AP[i]}")
|
||||
print(f"+ Class '{c}' ({class_names[c]}) - precision: {precision[i]}")
|
||||
print(f"+ Class '{c}' ({class_names[c]}) - recall: {recall[i]}")
|
||||
print(f"+ Class '{c}' ({class_names[c]}) - f1: {f1[i]}")
|
||||
|
||||
|
||||
print(f"mAP: {AP.mean()}")
|
||||
4
test.sh
Normal file
4
test.sh
Normal file
@ -0,0 +1,4 @@
|
||||
#!bash
|
||||
CARD=0,1
|
||||
|
||||
CUDA_VISIBLE_DEVICES=$CARD python test.py --model_def config/ds_1w_prune_0.8_xs_min_loss_yolov3-ds-person.cfg --weights_path weights/ds_1w_prune_0.8_xs_min_loss_yolov3_ckpt.pth --data_config config/person.data --class_path data/person.names --conf_thres 0.1
|
||||
277
test_prune.py
Normal file
277
test_prune.py
Normal file
@ -0,0 +1,277 @@
|
||||
from cgi import print_directory
|
||||
from models import *
|
||||
from utils.utils import *
|
||||
import torch
|
||||
import numpy as np
|
||||
from copy import deepcopy
|
||||
from test import evaluate
|
||||
from terminaltables import AsciiTable
|
||||
import time
|
||||
from utils.prune_utils import *
|
||||
|
||||
class opt():
|
||||
model_def = "config/yolov3-ds-person.cfg" # yolov3-ds8-person.cfg
|
||||
data_config = "config/smallperson.data" # smallperson.data
|
||||
model = 'checkpoints/yolov3_ckpt_99_05181112.pth' # checkpoints/yolov3_ckpt.pth' # res8 yolov3_ckpt_99_06081725.pth # 2*res8+res4 yolov3_ckpt_99_05181112
|
||||
|
||||
|
||||
#%%
|
||||
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
||||
model = Darknet(opt.model_def).to(device) #加载模型
|
||||
model.load_state_dict(torch.load(opt.model)) #加载权重
|
||||
# print(model)
|
||||
# for name in model.state_dict():
|
||||
# print(name)
|
||||
|
||||
data_config = parse_data_config(opt.data_config)
|
||||
valid_path = data_config["valid"]
|
||||
class_names = load_classes(data_config["names"])
|
||||
|
||||
# 用lambda表达式创建函数
|
||||
eval_model = lambda model:evaluate(model, path=valid_path, iou_thres=0.5, conf_thres=0.01,
|
||||
nms_thres=0.1, img_size=model.img_size, batch_size=8)
|
||||
# print(eval_model)
|
||||
|
||||
obtain_num_parameters = lambda model:sum([param.nelement() for param in model.parameters()])
|
||||
|
||||
# 获取最初的模型评估和参数量
|
||||
origin_model_metric = eval_model(model)
|
||||
origin_nparameters = obtain_num_parameters(model)
|
||||
|
||||
CBL_idx, Conv_idx, prune_idx= parse_module_defs(model.module_defs)
|
||||
# print(CBL_idx, Conv_idx, prune_idx)
|
||||
# CBL_idx = [0, 1, 2, 3, 5, 6, 7, 9, 10, 12, 13, 16, 19, 22, 25, 28, 31, 34, 37, 38, 41, 44, 47, 50, 53, 56, 59, 62, 63, 66,
|
||||
# 69, 72, 75, 76, 77, 78, 79, 80, 84, 87, 88, 89, 90, 91, 92, 96, 99, 100, 101, 102, 103, 104]
|
||||
# 问题是 CBL_idx中没有14就是ds_conv那一层
|
||||
|
||||
# Conv_idx = [81, 93, 105]
|
||||
# prune_idx = [0, 2, 6, 9, 75, 76, 77, 78, 79, 80, 87, 88, 89, 90, 91, 92, 99, 100, 101, 102, 103, 104]
|
||||
|
||||
#prune_idx =
|
||||
#[0, 2, 6, 9, 13, 16, 19, 22, 25, 28, 31, 34, 38, 41, 44, 47, 50, 53, 56, 59, 63, 66, 69, 72, 75,
|
||||
# 76, 77, 78, 79, 80, 87, 88, 89, 90, 91, 92, 99, 100, 101, 102, 103, 104]
|
||||
|
||||
bn_weights = gather_bn_weights(model.module_list, prune_idx)
|
||||
# print("model.module_list[0]:",model.module_list[0],"---",len(model.module_list[0]))
|
||||
# print('bn_weights = ' ,bn_weights, "---",len(bn_weights))
|
||||
|
||||
sorted_bn = torch.sort(bn_weights)[0] # 对bn从小到大排序
|
||||
# print('sorted_bn = ' ,sorted_bn)
|
||||
|
||||
# 避免剪掉所有channel的最高阈值(每个BN层的gamma的最大值的最小值即为阈值上限)
|
||||
highest_thre = []
|
||||
for idx in prune_idx:
|
||||
highest_thre.append(model.module_list[idx][1].weight.data.abs().max().item())
|
||||
highest_thre = min(highest_thre)
|
||||
|
||||
# 找到highest_thre对应的下标对应的百分比
|
||||
percent_limit = (sorted_bn==highest_thre).nonzero().item()/len(bn_weights)
|
||||
|
||||
print(f'Threshold should be less than {highest_thre:.4f}.')
|
||||
print(f'The corresponding prune ratio is {percent_limit:.3f}.')
|
||||
|
||||
#%%
|
||||
def prune_and_eval(model, sorted_bn, percent=.0):
|
||||
model_copy = deepcopy(model)
|
||||
thre_index = int(len(sorted_bn) * percent)
|
||||
# print('thre_index = ', thre_index) #thre_index = 11369
|
||||
thre = sorted_bn[thre_index]
|
||||
# print('thre = ', thre) #thre = tensor(0.0925)
|
||||
# print(model_copy)
|
||||
|
||||
print(f'Channels with Gamma value less than {thre:.4f} are pruned!')
|
||||
|
||||
remain_num = 0
|
||||
for idx in prune_idx:
|
||||
# prune_idx = [0, 2, 6, 9, 75, 76, 77, 78, 79, 80, 87, 88, 89, 90, 91, 92, 99, 100, 101, 102, 103, 104]
|
||||
# print("idx:",idx)
|
||||
bn_module = model_copy.module_list[idx][1]
|
||||
|
||||
mask = obtain_bn_mask(bn_module, thre) #生成mask
|
||||
# print(idx, ': ', len(mask))
|
||||
# print(idx, ':', len(mask), ':', mask)
|
||||
remain_num += int(mask.sum())
|
||||
# BN层的权重(gamma)乘以这个mask,就相当于剪枝了
|
||||
bn_module.weight.data.mul_(mask) # 用mask对原始权重进行操作
|
||||
# print("remain_num:",remain_num)
|
||||
# print(model_copy)
|
||||
# print(bn_module.weight.data)
|
||||
# model_copy.module_list[0][1] = BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
|
||||
# print(model_copy.module_list[0][1].weight.data)
|
||||
"""
|
||||
model_copy.module_list[0][1].weight.data =
|
||||
tensor([ 1.6235, 0.3670, 0.6683, 0.2203, -0.2113, 1.6356, 0.0717, 0.5802,
|
||||
0.1437, -0.3640, 0.2322, 0.2651, 0.7316, 0.6135, 1.6100, 0.8620,
|
||||
0.1987, 0.5357, 0.2006, 0.2127, 0.7190, -1.1396, -0.2585, -0.4673,
|
||||
0.0498, 0.5148, 0.7377, 0.3179, 1.2934, 1.1743, 0.2840, 0.2782],
|
||||
device='cuda:0')
|
||||
"""
|
||||
|
||||
mAP = eval_model(model_copy)[2].mean() # 搞明白为什么 剪枝之后sample_metrics = [] 为空列表了 : 剪枝率过高会为空
|
||||
# print(mAP)
|
||||
|
||||
print(f'Number of channels has been reduced from {len(sorted_bn)} to {remain_num}')
|
||||
print(f'Prune ratio: {1-remain_num/len(sorted_bn):.3f}')
|
||||
print(f'mAP of the pruned model is {mAP:.4f}')
|
||||
|
||||
return thre
|
||||
|
||||
#调用上面的函数
|
||||
percent = 0.85 # 0.85
|
||||
threshold = prune_and_eval(model, sorted_bn, percent)
|
||||
|
||||
# print(threshold)
|
||||
|
||||
#%%
|
||||
def obtain_filters_mask(model, thre, CBL_idx, prune_idx):
|
||||
|
||||
pruned = 0
|
||||
total = 0
|
||||
num_filters = []
|
||||
filters_mask = []
|
||||
for idx in CBL_idx:
|
||||
if(model.module_defs[idx]['type'] == 'ds_conv'):
|
||||
bn_module = model.module_list[idx][2]
|
||||
else:
|
||||
bn_module = model.module_list[idx][1]
|
||||
# print("idx",idx,"--bn_module :",model.module_list[idx][1])
|
||||
# 如果idx是在剪枝下标的列表中,就执行剪枝
|
||||
if idx in prune_idx:
|
||||
# prune_idx = [0, 2, 6, 9, 75, 76, 77, 78, 79, 80, 87, 88, 89, 90, 91, 92, 99, 100, 101, 102, 103, 104]
|
||||
|
||||
mask = obtain_bn_mask(bn_module, thre).cpu().numpy()
|
||||
# 保留的通道数
|
||||
remain = int(mask.sum())
|
||||
# 剪掉的通道数
|
||||
pruned = pruned + mask.shape[0] - remain
|
||||
|
||||
if remain == 0:
|
||||
print("Channels would be all pruned!")
|
||||
raise Exception
|
||||
|
||||
print(f'layer index: {idx:>3d} \t total channel: {mask.shape[0]:>4d} \t '
|
||||
f'remaining channel: {remain:>4d}')
|
||||
else:
|
||||
# 不用剪枝就全部保留
|
||||
mask = np.ones(bn_module.weight.data.shape)
|
||||
remain = mask.shape[0]
|
||||
|
||||
# print("idx:",idx,"--mask:",mask,"--lenofmask",len(mask)) # 怀疑这里因为ds_conv有两个卷积层 可能出现问题 但是14层的ds_conv mask长度是256 因为算的是bn层的mask,所以为256,这里值得注意!!明天来检查一下!
|
||||
|
||||
total += mask.shape[0]
|
||||
num_filters.append(remain) # 剪枝后还存在的滤波器
|
||||
filters_mask.append(mask.copy()) # 剪枝的掩码mask
|
||||
|
||||
# print("num_filters:",len(num_filters),"CBL_idx:", len(CBL_idx)) 都是72
|
||||
prune_ratio = pruned / total
|
||||
print(f'Prune channels: {pruned}\tPrune ratio: {prune_ratio:.3f}')
|
||||
|
||||
return num_filters, filters_mask
|
||||
|
||||
#调用上面的函数
|
||||
num_filters, filters_mask = obtain_filters_mask(model, threshold, CBL_idx, prune_idx)
|
||||
# print("num_filters : ", num_filters)
|
||||
# num_filters = [29, 64, 29, 64, 128, 59, 128, 61, 128, 256, 128, 256, 128, 256, 128, 256, 128, 256, 128, 256, 128, 256, 128, 256, 128, 256, 512,
|
||||
# 256, 512, 256, 512, 256, 512, 256, 512, 256, 512, 256, 512, 256, 512, 256, 512, 1024, 512, 1024, 512, 1024, 512, 1024, 512, 1024,
|
||||
# 264, 422, 237, 441, 263, 139, 256, 226, 352, 179, 278, 137, 215, 128, 111, 182, 90, 140, 54, 220]
|
||||
|
||||
#%%
|
||||
# 映射成一个字典,idx->mask
|
||||
CBLidx2mask = {idx: mask for idx, mask in zip(CBL_idx, filters_mask)}
|
||||
# print("CBLidx2mask:", CBLidx2mask)
|
||||
# 获得剪枝后的模型
|
||||
pruned_model = prune_model_keep_size(model, prune_idx, CBL_idx, CBLidx2mask)
|
||||
# print("pruned_model:",pruned_model)
|
||||
# 对剪枝后的模型进行评价
|
||||
pruned_model_metric = eval_model(pruned_model)
|
||||
print("mAP", f'{origin_model_metric[2].mean():.6f}', f'{pruned_model_metric[2].mean():.6f}')
|
||||
# pruned_nparameters = obtain_num_parameters(pruned_model)
|
||||
# print("pruned_nparameters:",pruned_nparameters)
|
||||
|
||||
#%%
|
||||
# 拷贝一份原始模型的参数
|
||||
compact_module_defs = deepcopy(model.module_defs)
|
||||
# 遍历需要剪枝的CBL模块,将通道数设置为剪枝后的通道数
|
||||
for idx, num in zip(CBL_idx, num_filters):
|
||||
# if compact_module_defs[idx]['type'] == 'ds_conv' :
|
||||
# # continue
|
||||
# compact_module_defs[idx]['filters'] = str(num)
|
||||
assert compact_module_defs[idx]['type'] == 'convolutional' or compact_module_defs[idx]['type'] == 'ds_conv'
|
||||
compact_module_defs[idx]['filters'] = str(num)
|
||||
# 改了网络结构,在这里相应的更改ds_conv通道数,先试试更改,如果后面不改,就在前面mask那里改改
|
||||
# assert compact_module_defs[idx]['type'] == 'ds_conv'
|
||||
# compact_module_defs[idx]['filters'] = str(num)
|
||||
# print("compact_module_defs:",compact_module_defs)
|
||||
|
||||
#%%
|
||||
#compact_model是剪枝之后的网络的真实结构(注意:上面的剪枝网络只是把那些需要剪枝的卷积层/BN层/激活层通道的权重置0了,并没有保存剪枝后的网络)
|
||||
# print("model.hyperparams:",model.hyperparams)
|
||||
compact_model = Darknet([model.hyperparams.copy()] + compact_module_defs).to(device)
|
||||
# compact_model_metric = eval_model(compact_model)
|
||||
# print("compact_model_metric:", "mAP", f'{compact_model_metric[2].mean():.6f}')
|
||||
# print("model.hyperparams:",model.hyperparams)
|
||||
# print("compact_model:", compact_model)
|
||||
# 计算参数量,MFLOPs
|
||||
compact_nparameters = obtain_num_parameters(compact_model)
|
||||
# print("compact_nparameters:", compact_nparameters) 18404269已经是剪完枝后的参数了
|
||||
# 为剪枝后的真实网络结构重新复制权重参数
|
||||
init_weights_from_loose_model(compact_model, pruned_model, CBL_idx, Conv_idx, CBLidx2mask)
|
||||
# 对比compact_model 与 prune_model每一层的权重
|
||||
# for name, parameters in pruned_model.named_parameters():
|
||||
# print(name, '1;', parameters.size())
|
||||
# for name, parameters in compact_model.named_parameters():
|
||||
# print(name, '2;', parameters.size())
|
||||
|
||||
# print("pruned_model:",pruned_model.state_dict())
|
||||
# print("compact_model:",compact_model.state_dict())
|
||||
|
||||
#%%
|
||||
random_input = torch.rand((1, 3, model.img_size, model.img_size)).to(device)
|
||||
|
||||
# 获取模型的推理时间
|
||||
def obtain_avg_forward_time(input, model, repeat=200):
|
||||
|
||||
model.eval()
|
||||
start = time.time()
|
||||
with torch.no_grad():
|
||||
for i in range(repeat):
|
||||
output = model(input)
|
||||
avg_infer_time = (time.time() - start) / repeat
|
||||
|
||||
return avg_infer_time, output
|
||||
|
||||
# 分别获取原始模型和剪枝后的模型的推理时间和输出
|
||||
pruned_forward_time, pruned_output = obtain_avg_forward_time(random_input, pruned_model)
|
||||
compact_forward_time, compact_output = obtain_avg_forward_time(random_input, compact_model)
|
||||
# print("pruned_forward_time:",pruned_forward_time,"---compact_forward_time:", compact_forward_time)
|
||||
# print("pruned_output:",pruned_output,"---compact_output:", compact_output)
|
||||
# 计算原始模型推理结果和剪枝后的模型的推理结果,如果差距比较大说明哪里错了
|
||||
# 先注释下面几行代码看能不能运行
|
||||
diff = (pruned_output-compact_output).abs().gt(0.001).sum().item()
|
||||
# print("diff:", diff)
|
||||
if diff > 0:
|
||||
print('Something wrong with the pruned model!')
|
||||
|
||||
#%%
|
||||
# 在测试集上测试剪枝后的模型, 并统计模型的参数数量
|
||||
compact_model_metric = eval_model(compact_model)
|
||||
|
||||
#%%
|
||||
# 比较剪枝前后参数数量的变化、指标性能的变化
|
||||
metric_table = [
|
||||
["Metric", "Before", "After"],
|
||||
["mAP", f'{origin_model_metric[2].mean():.6f}', f'{compact_model_metric[2].mean():.6f}'],
|
||||
["Parameters", f"{origin_nparameters}", f"{compact_nparameters}"],
|
||||
["Inference", f'{pruned_forward_time:.4f}', f'{compact_forward_time:.4f}']
|
||||
]
|
||||
print(AsciiTable(metric_table).table)
|
||||
|
||||
#%%
|
||||
# 生成剪枝后的cfg文件并保存模型
|
||||
pruned_cfg_name = opt.model_def.replace('/', f'/ds_1w_prune_{percent}_ckpt_99_05181112')
|
||||
pruned_cfg_file = write_cfg(pruned_cfg_name, [model.hyperparams.copy()] + compact_module_defs)
|
||||
print(f'Config file has been saved: {pruned_cfg_file}')
|
||||
|
||||
compact_model_name = opt.model.replace('/', f'/ds_1w_prune_{percent}_')
|
||||
torch.save(compact_model.state_dict(), compact_model_name)
|
||||
print(f'Compact model has been saved: {compact_model_name}')
|
||||
4
test_prune.sh
Normal file
4
test_prune.sh
Normal file
@ -0,0 +1,4 @@
|
||||
#!bash
|
||||
CARD=0,1
|
||||
|
||||
CUDA_VISIBLE_DEVICES=$CARD python test_prune.py
|
||||
15
testdict.py
Normal file
15
testdict.py
Normal file
@ -0,0 +1,15 @@
|
||||
import torch
|
||||
from models import *
|
||||
|
||||
class opt():
|
||||
model_def = "config/ds_1w_prune_0.5_yolov3-ds-person.cfg"
|
||||
data_config = "config/smallperson.data" # person.data
|
||||
model = 'checkpoints/ds_1w_prune_0.5_yolov3_ckpt_99_05181112.pth' # checkpoints/yolov3_ckpt.pth'
|
||||
|
||||
# 加载模型
|
||||
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
||||
model = Darknet(opt.model_def).to(device) #加载模型
|
||||
model.load_state_dict(torch.load(opt.model)) #加载权重
|
||||
|
||||
# 打印参数
|
||||
print(model)
|
||||
281
train.py
Normal file
281
train.py
Normal file
@ -0,0 +1,281 @@
|
||||
from __future__ import division
|
||||
|
||||
from models import *
|
||||
from utils.logger import *
|
||||
from utils.utils import *
|
||||
from utils.datasets import *
|
||||
from utils.parse_config import *
|
||||
from utils.prune_utils import *
|
||||
from test import evaluate
|
||||
|
||||
# 调试用的模块,reload用于代码热重载
|
||||
from importlib import reload
|
||||
import debug_utils
|
||||
|
||||
from terminaltables import AsciiTable
|
||||
|
||||
import os
|
||||
import time
|
||||
import datetime
|
||||
import argparse
|
||||
|
||||
# import logging
|
||||
|
||||
import torch
|
||||
from torch.utils.data import DataLoader
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--epochs", type=int, default=100, help="number of epochs")
|
||||
parser.add_argument("--batch_size", type=int, default=56, help="size of each image batch") # default=16
|
||||
parser.add_argument("--model_def", type=str, default="config/yolov3-person.cfg", help="path to model definition file") #default="config/yolov3-hand.cfg"
|
||||
parser.add_argument("--data_config", type=str, default="config/person.data", help="path to data config file") #default="config/oxfordhand.data"
|
||||
# parser.add_argument("--pretrained_weights", type=str, default="weights/darknet53.conv.74",
|
||||
parser.add_argument("--pretrained_weights", '-pre', type=str,
|
||||
default="weights/yolov3.weights", help="if specified starts from checkpoint model")
|
||||
parser.add_argument("--n_cpu", type=int, default=4, help="number of cpu threads to use during batch generation")
|
||||
parser.add_argument("--img_size", type=int, default=416, help="size of each image dimension")
|
||||
parser.add_argument("--checkpoint_interval", type=int, default=20, help="interval between saving model weights") #default=5
|
||||
parser.add_argument("--evaluation_interval", type=int, default=1, help="interval evaluations on validation set")
|
||||
parser.add_argument("--multiscale_training", default=False, help="allow for multi-scale training")
|
||||
parser.add_argument("--debug_file", type=str, default="debug", help="enter ipdb if dir exists")
|
||||
|
||||
parser.add_argument('--learning_rate', '-lr', dest='lr', type=float, default=1e-3, help='initial learning rate')
|
||||
|
||||
parser.add_argument('--sparsity-regularization', '-sr', dest='sr', action='store_true',
|
||||
help='train with channel sparsity regularization')
|
||||
parser.add_argument('--s', type=float, default=0.01, help='scale sparse rate')
|
||||
|
||||
opt = parser.parse_args()
|
||||
print(opt)
|
||||
|
||||
logger = Logger("logs")
|
||||
|
||||
# 设置随机数种子
|
||||
init_seeds()
|
||||
|
||||
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
||||
|
||||
timestamp = datetime.datetime.fromtimestamp(time.time()).strftime('%m%d%H%M')
|
||||
|
||||
os.makedirs("output", exist_ok=True)
|
||||
os.makedirs("checkpoints", exist_ok=True)
|
||||
|
||||
# Get data configuration
|
||||
data_config = parse_data_config(opt.data_config)
|
||||
train_path = data_config["train"]
|
||||
valid_path = data_config["valid"]
|
||||
class_names = load_classes(data_config["names"])
|
||||
|
||||
# Initiate model
|
||||
model = Darknet(opt.model_def).to(device)
|
||||
model.apply(weights_init_normal)
|
||||
|
||||
#打印模型
|
||||
# print(model)
|
||||
|
||||
# If specified we start from checkpoint
|
||||
#是否加载预训练模型
|
||||
# if opt.pretrained_weights:
|
||||
# if opt.pretrained_weights.endswith(".pth"):
|
||||
# model.load_state_dict(torch.load(opt.pretrained_weights))
|
||||
# else:
|
||||
# model.load_darknet_weights(opt.pretrained_weights)
|
||||
|
||||
_, _, prune_idx= parse_module_defs(model.module_defs) # 剪枝需要的参数S
|
||||
# prune_idx = \
|
||||
# [0,
|
||||
# 2,
|
||||
# 6, 9,
|
||||
# 13, 16, 19, 22, 25, 28, 31, 34,
|
||||
# 38, 41, 44, 47, 50, 53, 56, 59,
|
||||
# 63, 66, 69, 72,
|
||||
# 75, 76, 77, 78, 79, 80,
|
||||
# #84,
|
||||
# 87, 88, 89, 90, 91, 92,
|
||||
# #96,
|
||||
# 99,100,101,102,103, 104]
|
||||
|
||||
# Get dataloader 导入数据
|
||||
dataset = ListDataset(train_path, augment=True, multiscale=opt.multiscale_training)
|
||||
dataloader = torch.utils.data.DataLoader(
|
||||
dataset,
|
||||
batch_size=opt.batch_size,
|
||||
shuffle=True,
|
||||
num_workers=opt.n_cpu,
|
||||
pin_memory=True,
|
||||
collate_fn=dataset.collate_fn
|
||||
)
|
||||
|
||||
optimizer = torch.optim.SGD(model.parameters(), lr=opt.lr, momentum=0.9)
|
||||
|
||||
metrics = [
|
||||
"grid_size",
|
||||
"loss",
|
||||
"x", "y", "w", "h",
|
||||
"conf",
|
||||
"cls", "cls_acc",
|
||||
"recall50", "recall75",
|
||||
"precision",
|
||||
"conf_obj", "conf_noobj",
|
||||
]
|
||||
|
||||
|
||||
# 配置日志记录器
|
||||
# logger = logging.getLogger('my_logger')
|
||||
# logger.setLevel(logging.INFO)
|
||||
# handler = logging.FileHandler('log.txt')
|
||||
# handler.setFormatter(logging.Formatter('%(asctime)s %(levelname)s: %(message)s [in %(pathname)s:%(lineno)d]'))
|
||||
# logger.addHandler(handler)
|
||||
|
||||
|
||||
# TFLOPS = 0
|
||||
tmp_loss = 0
|
||||
min_loss = 100
|
||||
best_mAP = 0
|
||||
|
||||
for epoch in range(opt.epochs):
|
||||
|
||||
# 进入调试模式
|
||||
if os.path.exists(opt.debug_file):
|
||||
import ipdb
|
||||
ipdb.set_trace()
|
||||
|
||||
model.train()
|
||||
start_time = time.time()
|
||||
|
||||
sr_flag = get_sr_flag(epoch, opt.sr)
|
||||
|
||||
obtain_num_parameters = lambda model:sum([param.nelement() for param in model.parameters()])
|
||||
origin_nparameters = obtain_num_parameters(model)
|
||||
print("Parameters : ", f"{origin_nparameters}")
|
||||
print("Model size:", sum([p.numel() for name, p in model.named_parameters()])) # 输出模型大小
|
||||
|
||||
for batch_i, (_, imgs, targets) in enumerate(dataloader):
|
||||
batches_done = len(dataloader) * epoch + batch_i
|
||||
|
||||
imgs = imgs.to(device)
|
||||
targets = targets.to(device)
|
||||
|
||||
loss, outputs = model(imgs, targets)
|
||||
|
||||
optimizer.zero_grad()
|
||||
loss.backward()
|
||||
|
||||
BNOptimizer.updateBN(sr_flag, model.module_list, opt.s, prune_idx)
|
||||
|
||||
optimizer.step()
|
||||
|
||||
# acc = (outputs > 0.5).float().mean()
|
||||
# logger.info('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}, Acc: {:.4f}'.format(epoch, epoch, i+1, len(dataloader), loss.item(), acc.item()))
|
||||
|
||||
# ----------------
|
||||
# Log progress
|
||||
# ----------------
|
||||
|
||||
log_str = "\n---- [Epoch %d/%d, Batch %d/%d] ----\n" % (epoch, opt.epochs, batch_i, len(dataloader))
|
||||
|
||||
metric_table = [["Metrics", *[f"YOLO Layer {i}" for i in range(len(model.yolo_layers))]]]
|
||||
|
||||
# Log metrics at each YOLO layer
|
||||
formats = {m: "%.6f" for m in metrics}
|
||||
formats["grid_size"] = "%2d"
|
||||
formats["cls_acc"] = "%.2f%%"
|
||||
for metric in metrics:
|
||||
row_metrics = [formats[metric] % yolo.metrics.get(metric, 0) for yolo in model.yolo_layers]
|
||||
metric_table += [[metric, *row_metrics]]
|
||||
|
||||
log_str += AsciiTable(metric_table).table
|
||||
log_str += f"\nTotal loss {loss.item()}"
|
||||
|
||||
#记录每个batch的最后一次loss
|
||||
tmp_loss = loss.item()
|
||||
|
||||
# Determine approximate time left for epoch
|
||||
epoch_batches_left = len(dataloader) - (batch_i + 1)
|
||||
time_left = datetime.timedelta(seconds=epoch_batches_left * (time.time() - start_time) / (batch_i + 1))
|
||||
log_str += f"\n---- ETA {time_left}"
|
||||
|
||||
print(log_str)
|
||||
|
||||
# Tensorboard logging
|
||||
tensorboard_log = []
|
||||
for i, yolo in enumerate(model.yolo_layers):
|
||||
for name, metric in yolo.metrics.items():
|
||||
# 选择部分指标写入tensorboard
|
||||
if name not in {"grid_size", "x", "y", "w", "h", "cls_acc"}:
|
||||
tensorboard_log += [(f"{name}_{i+1}", metric)]
|
||||
tensorboard_log += [("loss", loss.item())]
|
||||
tensorboard_log += [("lr", optimizer.param_groups[0]['lr'])]
|
||||
logger.list_of_scalars_summary('train', tensorboard_log, batches_done)
|
||||
|
||||
|
||||
|
||||
if epoch % opt.evaluation_interval == 0:
|
||||
print("\n---- Evaluating Model ----")
|
||||
# Evaluate the model on the validation set
|
||||
precision, recall, AP, f1, ap_class = evaluate(
|
||||
model,
|
||||
path=valid_path,
|
||||
iou_thres=0.5,
|
||||
conf_thres=0.01,
|
||||
nms_thres=0.5,
|
||||
img_size=opt.img_size,
|
||||
batch_size=8,
|
||||
)
|
||||
evaluation_metrics = [
|
||||
("val_precision", precision.mean()),
|
||||
("val_recall", recall.mean()),
|
||||
("val_mAP", AP.mean()),
|
||||
("val_f1", f1.mean()),
|
||||
]
|
||||
logger.list_of_scalars_summary('valid', evaluation_metrics, epoch)
|
||||
|
||||
# Print class APs and mAP
|
||||
ap_table = [["Index", "Class name", "AP"]]
|
||||
for i, c in enumerate(ap_class):
|
||||
ap_table += [[c, class_names[c], "%.5f" % AP[i]]]
|
||||
print(AsciiTable(ap_table).table)
|
||||
print(f"---- mAP {AP.mean()}")
|
||||
|
||||
# 往tensorboard中记录bn权重分布
|
||||
bn_weights = gather_bn_weights(model.module_list, prune_idx)
|
||||
logger.writer.add_histogram('bn_weights/hist', bn_weights.numpy(), epoch, bins='doane')
|
||||
|
||||
if(best_mAP < AP.mean()):
|
||||
best_mAP = AP.mean()
|
||||
torch.save(model.state_dict(), f"checkpoints/xs_nopretrain_pt_best_mAP_{epoch}_yolov3_ckpt.pth") # 保存mAP最高的模型
|
||||
if(tmp_loss < min_loss):
|
||||
min_loss = tmp_loss
|
||||
torch.save(model.state_dict(), f"checkpoints/xs_nopretrain_pt_min_loss_{epoch}_yolov3_ckpt.pth") # 保存loss最低的模型
|
||||
|
||||
if epoch % opt.checkpoint_interval == 0 or epoch == opt.epochs - 1:
|
||||
|
||||
torch.save(model.state_dict(), f"checkpoints/xs_nopretrain_yolov3_ckpt_{epoch}_{timestamp}.pth")
|
||||
print(f"model has been saved:checkpoints/xs_nopretrain_yolov3_ckpt_{epoch}_{timestamp}.pth")
|
||||
|
||||
|
||||
|
||||
# obtain_num_parameters = lambda model:sum([param.nelement() for param in model.parameters()])
|
||||
# origin_nparameters = obtain_num_parameters(model)
|
||||
# print("Parameters : ", f"{origin_nparameters}")
|
||||
|
||||
# GPUs = torch.hub.list_hub_servers()
|
||||
# flops = []
|
||||
# parameters = []
|
||||
|
||||
# for server in GPUs:
|
||||
# # device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
||||
# flops.append(torch.Tensor(np.sum(np.square(model.parameters()[:3])).item()))
|
||||
# parameters.append(torch.Tensor(model.parameters()))
|
||||
# model.to(device)
|
||||
# flops = np.array(flops)
|
||||
# flops = flops.reshape(-1, flops.shape[-1])
|
||||
# TFLOPS += flops.item()
|
||||
# parameters = np.array(parameters)
|
||||
# parameters = parameters.reshape(-1, parameters.shape[-1])
|
||||
# print('GPUs:', GPUs)
|
||||
# print('FLOPS:', flops.item())
|
||||
# print('Params:', parameters.item())
|
||||
|
||||
# print('TFLOPS:', TFLOPS)
|
||||
4
train_person.sh
Normal file
4
train_person.sh
Normal file
@ -0,0 +1,4 @@
|
||||
#!bash
|
||||
CARD=0,1
|
||||
|
||||
CUDA_VISIBLE_DEVICES=$CARD python train.py --model_def config/yolov3-person.cfg
|
||||
BIN
utils/__pycache__/augmentations.cpython-38.pyc
Normal file
BIN
utils/__pycache__/augmentations.cpython-38.pyc
Normal file
Binary file not shown.
BIN
utils/__pycache__/augmentations.cpython-39.pyc
Normal file
BIN
utils/__pycache__/augmentations.cpython-39.pyc
Normal file
Binary file not shown.
BIN
utils/__pycache__/datasets.cpython-38.pyc
Normal file
BIN
utils/__pycache__/datasets.cpython-38.pyc
Normal file
Binary file not shown.
BIN
utils/__pycache__/datasets.cpython-39.pyc
Normal file
BIN
utils/__pycache__/datasets.cpython-39.pyc
Normal file
Binary file not shown.
BIN
utils/__pycache__/logger.cpython-38.pyc
Normal file
BIN
utils/__pycache__/logger.cpython-38.pyc
Normal file
Binary file not shown.
BIN
utils/__pycache__/logger.cpython-39.pyc
Normal file
BIN
utils/__pycache__/logger.cpython-39.pyc
Normal file
Binary file not shown.
BIN
utils/__pycache__/parse_config.cpython-38.pyc
Normal file
BIN
utils/__pycache__/parse_config.cpython-38.pyc
Normal file
Binary file not shown.
BIN
utils/__pycache__/parse_config.cpython-39.pyc
Normal file
BIN
utils/__pycache__/parse_config.cpython-39.pyc
Normal file
Binary file not shown.
BIN
utils/__pycache__/prune_utils.cpython-38.pyc
Normal file
BIN
utils/__pycache__/prune_utils.cpython-38.pyc
Normal file
Binary file not shown.
BIN
utils/__pycache__/utils.cpython-38.pyc
Normal file
BIN
utils/__pycache__/utils.cpython-38.pyc
Normal file
Binary file not shown.
BIN
utils/__pycache__/utils.cpython-39.pyc
Normal file
BIN
utils/__pycache__/utils.cpython-39.pyc
Normal file
Binary file not shown.
42
utils/augmentations.py
Normal file
42
utils/augmentations.py
Normal file
@ -0,0 +1,42 @@
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
import numpy as np
|
||||
import albumentations as A
|
||||
|
||||
# boxes = (cls, x, y, w, h)
|
||||
def horizontal_flip(images, boxes):
|
||||
images = np.flip(images, [-1])
|
||||
boxes[:, 1] = 1 - boxes[:, 1]
|
||||
return images, boxes
|
||||
|
||||
# images[np.unit8], boxes[numpy] = (cls, x, y, w, h)
|
||||
def augment(image, boxes):
|
||||
h, w, _ = image.shape
|
||||
labels, boxes_coord = boxes[:, 0], boxes[:, 1:]
|
||||
labels = labels.tolist()
|
||||
boxes_coord = boxes_coord * h # 得到原图尺寸下的坐标(未归一化的坐标)
|
||||
boxes_coord[:, 0] = np.clip(boxes_coord[:, 0]-boxes_coord[:, 2]/2, a_min=0, a_max=None) # 确保x_min和y_min有效
|
||||
boxes_coord[:, 1] = np.clip(boxes_coord[:, 1]-boxes_coord[:, 3]/2, a_min=0, a_max=None)
|
||||
boxes_coord = boxes_coord.tolist() # [x_min, y_min, width, height]
|
||||
|
||||
# 在这里设置数据增强的方法
|
||||
aug = A.Compose([
|
||||
A.HorizontalFlip(p=0.5),
|
||||
# A.HueSaturationValue(hue_shift_limit=10, sat_shift_limit=10, val_shift_limit=10, p=0.5),
|
||||
# A.ShiftScaleRotate(shift_limit=0.1, scale_limit=0.1, rotate_limit=5, border_mode=0, p=0.5)
|
||||
], bbox_params={'format':'coco', 'label_fields': ['category_id']})
|
||||
|
||||
augmented = aug(image=image, bboxes=boxes_coord, category_id=labels)
|
||||
|
||||
# 经过aug之后,如果把boxes变没了,则返回原来的图片
|
||||
if augmented['bboxes']:
|
||||
image = augmented['image']
|
||||
|
||||
boxes_coord = np.array(augmented['bboxes']) # x_min, y_min, w, h → x, y, w, h
|
||||
boxes_coord[:, 0] = boxes_coord[:, 0] + boxes_coord[:, 2]/2
|
||||
boxes_coord[:, 1] = boxes_coord[:, 1] + boxes_coord[:, 3]/2
|
||||
boxes_coord = boxes_coord / h
|
||||
labels = np.array(augmented['category_id'])[:, None]
|
||||
boxes = np.concatenate((labels, boxes_coord), 1)
|
||||
|
||||
return image, boxes
|
||||
173
utils/datasets.py
Normal file
173
utils/datasets.py
Normal file
@ -0,0 +1,173 @@
|
||||
import glob
|
||||
import random
|
||||
import os
|
||||
import sys
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
|
||||
from utils.augmentations import augment
|
||||
from torch.utils.data import Dataset
|
||||
import torchvision.transforms as transforms
|
||||
|
||||
# 图像的转换流程:PIL→numpy→pad→transform→tensor
|
||||
|
||||
# 对numpy格式的img进行padding([0,255])
|
||||
def pad_to_square(img, pad_value):
|
||||
h, w, _ = img.shape
|
||||
dim_diff = np.abs(h - w)
|
||||
# (upper / left) padding and (lower / right) padding
|
||||
pad1, pad2 = dim_diff // 2, dim_diff - dim_diff // 2
|
||||
# Determine padding
|
||||
pad = ((pad1, pad2), (0,0), (0,0)) if h <= w else ((0,0), (pad1, pad2), (0,0)) # 分别对应h,w,c的padding
|
||||
# Add padding
|
||||
img = np.pad(img, pad, 'constant', constant_values=pad_value)
|
||||
|
||||
return img, (*pad[1], *pad[0]) # 返回w,c的padding
|
||||
|
||||
|
||||
# 对tensor格式的img进行resize
|
||||
def resize(image, size):
|
||||
image = F.interpolate(image.unsqueeze(0), size=size, mode="nearest").squeeze(0)
|
||||
return image
|
||||
|
||||
|
||||
class ImageFolder(Dataset):
|
||||
def __init__(self, folder_path, img_size=416):
|
||||
self.files = sorted(glob.glob("%s/*.*" % folder_path))
|
||||
self.img_size = img_size
|
||||
|
||||
def __getitem__(self, index):
|
||||
img_path = self.files[index % len(self.files)]
|
||||
|
||||
img = Image.open(img_path)
|
||||
img = np.array(img)
|
||||
|
||||
# Pad to square resolution
|
||||
img, _ = pad_to_square(img, 0)
|
||||
|
||||
img = transforms.ToTensor()(img) # img为np.uint8格式
|
||||
|
||||
# Resize
|
||||
img = resize(img, self.img_size)
|
||||
|
||||
return img_path, img
|
||||
|
||||
def __len__(self):
|
||||
return len(self.files)
|
||||
|
||||
|
||||
class ListDataset(Dataset):
|
||||
def __init__(self, list_path, img_size=416, augment=True, multiscale=True, normalized_labels=True):
|
||||
with open(list_path, "r") as file:
|
||||
self.img_files = file.readlines()
|
||||
|
||||
self.label_files = [
|
||||
path.replace("images", "labels").replace(".png", ".txt").replace(".jpg", ".txt")
|
||||
for path in self.img_files
|
||||
]
|
||||
self.img_size = img_size
|
||||
self.augment = augment
|
||||
self.multiscale = multiscale
|
||||
self.normalized_labels = normalized_labels
|
||||
self.min_size = self.img_size - 3 * 32
|
||||
self.max_size = self.img_size + 3 * 32
|
||||
self.batch_count = 0
|
||||
|
||||
def __getitem__(self, index):
|
||||
|
||||
# ---------
|
||||
# Image
|
||||
# ---------
|
||||
|
||||
img_path = self.img_files[index % len(self.img_files)].rstrip()
|
||||
|
||||
img = Image.open(img_path).convert('RGB')
|
||||
img = np.array(img)
|
||||
|
||||
# Handle images with less than three channels
|
||||
if len(img.shape) != 3:
|
||||
img = img[None, :, :]
|
||||
img = img.repeat(3, 0)
|
||||
|
||||
h, w, _ = img.shape # np格式的img是H*W*C
|
||||
h_factor, w_factor = (h, w) if self.normalized_labels else (1, 1)
|
||||
# Pad to square resolution
|
||||
img, pad = pad_to_square(img, 0)
|
||||
padded_h, padded_w, _ = img.shape
|
||||
|
||||
# ---------
|
||||
# Label
|
||||
# ---------
|
||||
|
||||
label_path = self.label_files[index % len(self.img_files)].rstrip()
|
||||
# print(label_path)
|
||||
|
||||
assert os.path.exists(label_path) # 确保label_path必定存在,即图片必定存在label
|
||||
boxes = np.loadtxt(label_path).reshape(-1, 5)
|
||||
# Extract coordinates for unpadded + unscaled image
|
||||
x1 = w_factor * (boxes[:, 1] - boxes[:, 3] / 2)
|
||||
y1 = h_factor * (boxes[:, 2] - boxes[:, 4] / 2)
|
||||
x2 = w_factor * (boxes[:, 1] + boxes[:, 3] / 2)
|
||||
y2 = h_factor * (boxes[:, 2] + boxes[:, 4] / 2)
|
||||
# Adjust for added padding
|
||||
x1 += pad[0] # pad是从低维到高维的,感觉这样写是有问题的,应该只与pad[0][2]有关,不过一般都是相等的
|
||||
y1 += pad[2]
|
||||
x2 += pad[0]
|
||||
y2 += pad[2]
|
||||
# Returns (x, y, w, h)
|
||||
boxes[:, 1] = ((x1 + x2) / 2) / padded_w
|
||||
boxes[:, 2] = ((y1 + y2) / 2) / padded_h
|
||||
boxes[:, 3] *= w_factor / padded_w # 原来的数值是boxw_ori/imgw_ori, 现在变成了(boxw_ori/imgw_ori)*imgw_ori/imgw_pad=boxw_ori/imgw_pad
|
||||
boxes[:, 4] *= h_factor / padded_h
|
||||
|
||||
# Apply augmentations
|
||||
# img, 以最长边为标准进行padding得到的uint8图像
|
||||
# boxes, (cls, x, y, w, h)都以pad后得到的img的高度进行了归一化
|
||||
if self.augment:
|
||||
img, boxes = augment(img, boxes)
|
||||
|
||||
img = transforms.ToTensor()(img) # ToTensor已经将像素值进行了归一化
|
||||
|
||||
targets = torch.zeros((len(boxes), 6))
|
||||
targets[:, 1:] = torch.from_numpy(boxes) # 0维在collate_fn中是作为idx用了,用于指定target对应的图片
|
||||
|
||||
return img_path, img, targets
|
||||
|
||||
def collate_fn(self, batch):
|
||||
paths, imgs, targets = list(zip(*batch))
|
||||
# Remove empty placeholder targets
|
||||
# 确保每一张图片都有box,如果某张图片没有标签就会报错!
|
||||
for boxes in targets:
|
||||
assert (boxes is not None)
|
||||
targets = [boxes for boxes in targets if boxes is not None] # 注意注意!!!这里并没有处理对应的imgs,imgs有可能与targets匹配不上
|
||||
# Add sample index to targets
|
||||
for i, boxes in enumerate(targets):
|
||||
boxes[:, 0] = i
|
||||
targets = torch.cat(targets, 0)
|
||||
# Selects new image size every tenth batch
|
||||
# 因为多线程并行读取的原因,self.batch_count和self.img_size的操作是不对的,
|
||||
# 个人觉得更好的处理方法将尺度的变化放到训练阶段,即读取数据之后再做resize
|
||||
# if self.multiscale:
|
||||
# self.img_size = random.choice(range(self.min_size, self.max_size + 1, 32))
|
||||
# Resize images to input shape
|
||||
if self.multiscale:
|
||||
imgs = torch.stack([resize(img, self.max_size) for img in imgs]) # 先将img统一resize到最大值
|
||||
else:
|
||||
imgs = torch.stack([resize(img, self.img_size) for img in imgs])
|
||||
return paths, imgs, targets
|
||||
|
||||
def __len__(self):
|
||||
return len(self.img_files)
|
||||
|
||||
# 重新设置img_size
|
||||
def select_new_img_size(self):
|
||||
self.img_size = random.choice(range(self.min_size, self.max_size + 1, 32))
|
||||
|
||||
# 对tensor格式的img进行resize
|
||||
def resize_imgs(self, images):
|
||||
if self.multiscale:
|
||||
images = F.interpolate(images, size=self.img_size, mode="nearest")
|
||||
|
||||
return images
|
||||
32
utils/logger.py
Normal file
32
utils/logger.py
Normal file
@ -0,0 +1,32 @@
|
||||
# import tensorflow as tf
|
||||
|
||||
# class Logger(object):
|
||||
# def __init__(self, log_dir):
|
||||
# """Create a summary writer logging to log_dir."""
|
||||
# self.writer = tf.summary.FileWriter(log_dir)
|
||||
#
|
||||
# def scalar_summary(self, tag, value, step):
|
||||
# """Log a scalar variable."""
|
||||
# summary = tf.Summary(value=[tf.Summary.Value(tag=tag, simple_value=value)])
|
||||
# self.writer.add_summary(summary, step)
|
||||
#
|
||||
# def list_of_scalars_summary(self, tag_value_pairs, step):
|
||||
# """Log scalar variables."""
|
||||
# summary = tf.Summary(value=[tf.Summary.Value(tag=tag, simple_value=value) for tag, value in tag_value_pairs])
|
||||
# self.writer.add_summary(summary, step)
|
||||
|
||||
from tensorboardX import SummaryWriter
|
||||
import os
|
||||
from datetime import datetime
|
||||
import time
|
||||
|
||||
class Logger(object):
|
||||
def __init__(self, log_dir):
|
||||
"""Create a summary writer logging to log_dir."""
|
||||
timestamp = datetime.fromtimestamp(time.time()).strftime('%m%d-%H:%M')
|
||||
self.writer = SummaryWriter(os.path.join(log_dir, timestamp))
|
||||
|
||||
def list_of_scalars_summary(self, prefix, tag_value_pairs, step):
|
||||
"""Log scalar variables."""
|
||||
for tag, value in tag_value_pairs:
|
||||
self.writer.add_scalar(prefix+'/'+tag, value, step)
|
||||
36
utils/parse_config.py
Normal file
36
utils/parse_config.py
Normal file
@ -0,0 +1,36 @@
|
||||
|
||||
|
||||
def parse_model_config(path):
|
||||
"""Parses the yolo-v3 layer configuration file and returns module definitions"""
|
||||
file = open(path, 'r')
|
||||
lines = file.read().split('\n')
|
||||
lines = [x for x in lines if x and not x.startswith('#')]
|
||||
lines = [x.rstrip().lstrip() for x in lines] # get rid of fringe whitespaces
|
||||
module_defs = []
|
||||
for line in lines:
|
||||
if line.startswith('['): # This marks the start of a new block
|
||||
module_defs.append({})
|
||||
module_defs[-1]['type'] = line[1:-1].rstrip()
|
||||
if module_defs[-1]['type'] == 'convolutional':
|
||||
module_defs[-1]['batch_normalize'] = 0
|
||||
else:
|
||||
key, value = line.split("=")
|
||||
value = value.strip()
|
||||
module_defs[-1][key.rstrip()] = value.strip()
|
||||
|
||||
return module_defs
|
||||
|
||||
def parse_data_config(path):
|
||||
"""Parses the data configuration file"""
|
||||
options = dict()
|
||||
# options['gpus'] = '0,1,2,3'
|
||||
# options['num_workers'] = '10'
|
||||
with open(path, 'r') as fp:
|
||||
lines = fp.readlines()
|
||||
for line in lines:
|
||||
line = line.strip()
|
||||
if line == '' or line.startswith('#'):
|
||||
continue
|
||||
key, value = line.split('=')
|
||||
options[key.strip()] = value.strip()
|
||||
return options
|
||||
290
utils/prune_utils.py
Normal file
290
utils/prune_utils.py
Normal file
@ -0,0 +1,290 @@
|
||||
import torch
|
||||
from terminaltables import AsciiTable
|
||||
from copy import deepcopy
|
||||
import numpy as np
|
||||
import torch.nn.functional as F
|
||||
|
||||
|
||||
def get_sr_flag(epoch, sr):
|
||||
# return epoch >= 5 and sr
|
||||
return sr
|
||||
|
||||
|
||||
def parse_module_defs(module_defs):
|
||||
|
||||
CBL_idx = []
|
||||
Conv_idx = []
|
||||
for i, module_def in enumerate(module_defs):
|
||||
# 添加了 or module_def['type'] == 'ds_conv' 将ds_conv也纳入剪枝范围,如果不考虑的话就在下面的不需要剪枝那里添加
|
||||
if module_def['type'] == 'convolutional' or module_def['type'] == 'ds_conv':
|
||||
if module_def['batch_normalize'] == '1':
|
||||
CBL_idx.append(i)
|
||||
#CBL_idx= 即为有卷积也有bn的层的idx
|
||||
#[0, 1, 2, 3, 5, 6, 7, 9, 10, 12, 13, 14, 16, 17, 19, 20, 22, 23, 25, 26, 28, 29, 31, 32, 34, 35, 37, 38,
|
||||
# 39, 41, 42, 44, 45, 47, 48, 50, 51, 53, 54, 56, 57, 59, 60, 62, 63, 64, 66, 67, 69, 70, 72, 73, 75, 76, 77,
|
||||
# 78, 79, 80, 84, 87, 88, 89, 90, 91, 92, 96, 99, 100, 101, 102, 103, 104]
|
||||
else:
|
||||
#Conv_idx = [81, 93, 105] 即为有卷积没有bn的层的idx
|
||||
Conv_idx.append(i)
|
||||
|
||||
ignore_idx = set() #哪些层不需要剪枝
|
||||
for i, module_def in enumerate(module_defs):
|
||||
#将ds_conv纳入不剪枝范围
|
||||
if module_def['type'] == 'ds_conv':
|
||||
ignore_idx.add(i-1)
|
||||
|
||||
if module_def['type'] == 'shortcut':
|
||||
ignore_idx.add(i-1)
|
||||
identity_idx = (i + int(module_def['from']))
|
||||
if module_defs[identity_idx]['type'] == 'convolutional':
|
||||
ignore_idx.add(identity_idx)
|
||||
elif module_defs[identity_idx]['type'] == 'shortcut':
|
||||
ignore_idx.add(identity_idx - 1)
|
||||
|
||||
ignore_idx.add(84)
|
||||
ignore_idx.add(96)
|
||||
# print(ignore_idx)
|
||||
#ignore_idx={1, 3, 5, 7, 10, 12, 14, 17, 20, 23, 26, 29, 32, 35, 37, 39, 42, 45, 48, 51, 54, 57, 60, 62, 64, 67, 70, 73, 84, 96} 改结构前
|
||||
# ignore_idx={1, 3, 5, 7, 10, 12, 13, 14, 16, 17, 19, 20, 22, 23, 25, 26, 28, 29, 31, 32, 34, 35, 37, 38, 39, 41, 42, 44, 45, 47,
|
||||
# 48, 50, 51, 53, 54, 56, 57, 59, 60, 62, 63, 64, 66, 67, 69, 70, 72, 73, 84, 96}
|
||||
prune_idx = [idx for idx in CBL_idx if idx not in ignore_idx]
|
||||
#prune_idx =[0, 2, 6, 9, 13, 16, 19, 22, 25, 28, 31, 34, 38, 41, 44, 47, 50, 53, 56, 59, 63, 66, 69, 72, 75,
|
||||
# 76, 77, 78, 79, 80, 87, 88, 89, 90, 91, 92, 99, 100, 101, 102, 103, 104] 改结构前
|
||||
# prune_idx = [0, 2, 6, 9, 75, 76, 77, 78, 79, 80, 87, 88, 89, 90, 91, 92, 99, 100, 101, 102, 103, 104]
|
||||
# 返回CBL组件的id,单独的Conv层的id,以及需要被剪枝的层的id
|
||||
return CBL_idx, Conv_idx, prune_idx
|
||||
|
||||
|
||||
def gather_bn_weights(module_list, prune_idx):
|
||||
|
||||
size_list = [module_list[idx][1].weight.data.shape[0] for idx in prune_idx] # 存储prune_idx对应层的 filter数量
|
||||
# print('module_list[0][1].weight.data.shape[0] = ',module_list[0][1].weight.data.shape[0])
|
||||
# print("size_list:",size_list)
|
||||
# ds_conv对应的size_list [32, 32, 64, 64, 512, 1024, 512, 1024, 512, 1024, 256, 512, 256, 512, 256, 512, 128, 256, 128, 256, 128, 256]
|
||||
#[32, 32, 64, 64, 128, 128, 128, 128, 128, 128, 128, 128, 256, 256, 256, 256, 256, 256, 256, 256, 512, 512, 512, 512, 512,
|
||||
# 1024, 512, 1024, 512, 1024, 256, 512, 256, 512, 256, 512, 128, 256, 128, 256, 128, 256]
|
||||
|
||||
bn_weights = torch.zeros(sum(size_list))
|
||||
# print('bn_weights = ', bn_weights)
|
||||
# bn_weights == tensor([0., 0., 0., ..., 0., 0., 0.])
|
||||
index = 0
|
||||
|
||||
for idx, size in zip(prune_idx, size_list):
|
||||
# print('idx = ' ,idx, ' | size = ',size)
|
||||
bn_weights[index:(index + size)] = module_list[idx][1].weight.data.abs().clone()
|
||||
index += size
|
||||
# print('bn_weights = ' ,bn_weights, ' | index = ',index)
|
||||
# print('module_list[0][1].weight.data.abs().clone()_len = ',len(module_list[0][1].weight.data.abs().clone()))
|
||||
# 获取CBL组件的BN层的权重,即Gamma参数,我们会根据这个参数来剪枝
|
||||
return bn_weights
|
||||
|
||||
|
||||
def write_cfg(cfg_file, module_defs):
|
||||
|
||||
with open(cfg_file, 'w') as f:
|
||||
for module_def in module_defs:
|
||||
f.write(f"[{module_def['type']}]\n")
|
||||
for key, value in module_def.items():
|
||||
if key != 'type':
|
||||
f.write(f"{key}={value}\n")
|
||||
f.write("\n")
|
||||
return cfg_file
|
||||
|
||||
|
||||
class BNOptimizer():
|
||||
|
||||
@staticmethod
|
||||
def updateBN(sr_flag, module_list, s, prune_idx):
|
||||
if sr_flag:
|
||||
for idx in prune_idx:
|
||||
# Squential(Conv, BN, Lrelu)
|
||||
bn_module = module_list[idx][1]
|
||||
# 将批标准化模块(bn_module)的权重矩阵的梯度乘以一个缩放因子后添加到该权重矩阵的梯度上。
|
||||
bn_module.weight.grad.data.add_(s * torch.sign(bn_module.weight.data)) # L1
|
||||
|
||||
|
||||
def obtain_quantiles(bn_weights, num_quantile=5):
|
||||
|
||||
sorted_bn_weights, i = torch.sort(bn_weights)
|
||||
total = sorted_bn_weights.shape[0]
|
||||
quantiles = sorted_bn_weights.tolist()[-1::-total//num_quantile][::-1]
|
||||
print("\nBN weights quantile:")
|
||||
quantile_table = [
|
||||
[f'{i}/{num_quantile}' for i in range(1, num_quantile+1)],
|
||||
["%.3f" % quantile for quantile in quantiles]
|
||||
]
|
||||
print(AsciiTable(quantile_table).table)
|
||||
|
||||
return quantiles
|
||||
|
||||
|
||||
def get_input_mask(module_defs, idx, CBLidx2mask):
|
||||
# print("CBLidx2mask : ", CBLidx2mask)
|
||||
if idx == 0:
|
||||
return np.ones(3)
|
||||
|
||||
if module_defs[idx - 1]['type'] == 'convolutional':
|
||||
return CBLidx2mask[idx - 1]
|
||||
elif module_defs[idx - 1]['type'] == 'ds_conv':
|
||||
return CBLidx2mask[idx - 1]
|
||||
elif module_defs[idx - 1]['type'] == 'shortcut':
|
||||
return CBLidx2mask[idx - 2]
|
||||
elif module_defs[idx - 1]['type'] == 'route':
|
||||
route_in_idxs = []
|
||||
for layer_i in module_defs[idx - 1]['layers'].split(","):
|
||||
if int(layer_i) < 0:
|
||||
route_in_idxs.append(idx - 1 + int(layer_i))
|
||||
else:
|
||||
route_in_idxs.append(int(layer_i))
|
||||
if len(route_in_idxs) == 1:
|
||||
return CBLidx2mask[route_in_idxs[0]]
|
||||
elif len(route_in_idxs) == 2:
|
||||
return np.concatenate([CBLidx2mask[in_idx - 1] for in_idx in route_in_idxs])
|
||||
else:
|
||||
print("Something wrong with route module!")
|
||||
raise Exception
|
||||
|
||||
|
||||
def init_weights_from_loose_model(compact_model, loose_model, CBL_idx, Conv_idx, CBLidx2mask):
|
||||
|
||||
# (14): Sequential(
|
||||
# (ds_conv_d_14): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128)
|
||||
# (ds_conv_p_14): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1))
|
||||
# (batch_norm_14): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
|
||||
# (leaky_14): LeakyReLU(negative_slope=0.1, inplace=True)
|
||||
# )
|
||||
|
||||
for idx in CBL_idx:
|
||||
compact_CBL = compact_model.module_list[idx]
|
||||
loose_CBL = loose_model.module_list[idx]
|
||||
# print("idx:",idx,"--compact_CBL :", compact_CBL, "--compact_CBL[1] :", compact_CBL[1],"--compact_CBL[2] :", compact_CBL[2])
|
||||
# print("idx:",idx,"--loose_CBL :", loose_CBL, "--loose_CBL[1] :", loose_CBL[1],"--loose_CBL[2] :", loose_CBL[2])
|
||||
# np.argwhere返回非0元素的索引,X[:,0]是numpy中数组的一种写法,表示对一个二维数组,取该二维数组第一维中的所有数据,第二维中取第0个数据
|
||||
out_channel_idx = np.argwhere(CBLidx2mask[idx])[:, 0].tolist()
|
||||
# print("idx:",idx,"--out_channel_idx:", len(out_channel_idx))
|
||||
# if (idx == 14):
|
||||
# print("idx:",idx,"--out_channel_idx:", out_channel_idx, "--len:",len(out_channel_idx))
|
||||
# print("CBLidx2mask[idx] :",CBLidx2mask[idx],"--len:",len(CBLidx2mask[idx]))
|
||||
# print("loose_model.module_list[idx][1]:",loose_model.module_list[idx][1])
|
||||
|
||||
|
||||
# 获取剪枝后的模型当前BN层的权重
|
||||
if(compact_model.module_defs[idx]['type'] == 'ds_conv') :
|
||||
compact_bn, loose_bn = compact_CBL[2], loose_CBL[2]
|
||||
else:
|
||||
compact_bn, loose_bn = compact_CBL[1], loose_CBL[1]
|
||||
# if idx==14:
|
||||
# print("compact_bn.weight.data:",compact_bn.weight.data,"--len",len(compact_bn.weight.data))
|
||||
# print("loose_bn.weight.data:",loose_bn.weight.data,"--len",len(loose_bn.weight.data))
|
||||
# print("loose_bn.weight.data[out_channel_idx]:", loose_bn.weight.data[out_channel_idx],"--len",len(loose_bn.weight.data[out_channel_idx]))
|
||||
compact_bn.weight.data = loose_bn.weight.data[out_channel_idx].clone()
|
||||
compact_bn.bias.data = loose_bn.bias.data[out_channel_idx].clone()
|
||||
compact_bn.running_mean.data = loose_bn.running_mean.data[out_channel_idx].clone()
|
||||
compact_bn.running_var.data = loose_bn.running_var.data[out_channel_idx].clone()
|
||||
|
||||
# 获取剪枝后的模型当前卷积层的权重,这和上一个卷积层的剪枝情况有关
|
||||
# print("idx:",idx)
|
||||
input_mask = get_input_mask(loose_model.module_defs, idx, CBLidx2mask)
|
||||
in_channel_idx = np.argwhere(input_mask)[:, 0].tolist()
|
||||
# if (idx == 14):
|
||||
# print("idx:",idx,"--in_channel_idx:", in_channel_idx, "--len:",len(in_channel_idx))
|
||||
# print("idx:",idx,"--in_channel_idx:",len(in_channel_idx))
|
||||
if(compact_model.module_defs[idx]['type'] == 'ds_conv') :
|
||||
compact_conv, loose_conv = compact_CBL[0], loose_CBL[0]
|
||||
# compact_conv, loose_conv = compact_CBL[1], loose_CBL[1]
|
||||
compact_conv2, loose_conv2 = compact_CBL[1], loose_CBL[1]
|
||||
|
||||
# 拷贝权重到剪枝后的模型中去
|
||||
# print("loose_conv2.weight.data:",loose_conv2.weight.data,"--len:",len(loose_conv2.weight.data))
|
||||
# print("loose_conv2.weight.data[:, in_channel_idx, :, :]:",loose_conv2.weight.data[:, in_channel_idx, :, :],"--len:",len(loose_conv2.weight.data[:, in_channel_idx, :, :]))
|
||||
# print("compact_conv.weight.data:",compact_conv.weight.data,"--len:",len(compact_conv.weight.data))
|
||||
# print("compact_conv2.weight.data:",compact_conv2.weight.data,"--len:",len(compact_conv2.weight.data))
|
||||
# print("loose_conv.weight.data:",loose_conv.weight.data,"--len:",len(loose_conv.weight.data))
|
||||
# print("loose_conv.weight.data[:, in_channel_idx, :, :]:",loose_conv.weight.data[:, in_channel_idx, :, :],"--len:",len(loose_conv.weight.data[:, in_channel_idx, :, :]))
|
||||
# tmp1 = loose_conv.weight.data[:, in_channel_idx, :, :].clone()
|
||||
# compact_conv.weight.data = tmp1[in_channel_idx, :, :, :].clone()
|
||||
compact_conv.weight.data = loose_conv.weight.data.clone()
|
||||
compact_conv.bias.data = loose_conv.bias.data.clone()
|
||||
# tmp2 = loose_conv2.weight.data[:, in_channel_idx, :, :].clone()
|
||||
# compact_conv2.weight.data = tmp2[out_channel_idx, :, :, :].clone()
|
||||
compact_conv2.weight.data = loose_conv2.weight.data.clone()
|
||||
compact_conv2.bias.data = loose_conv2.bias.data.clone()
|
||||
else:
|
||||
compact_conv, loose_conv = compact_CBL[0], loose_CBL[0]
|
||||
# print("idx:",idx,"--compact_CBL[0]:",compact_CBL[0],"--loose_CBL[0]",loose_CBL[0]) #还有一个可能就是ds_conv中有两个卷积层都需要复制权重!
|
||||
# print("idx:",idx,"--compact_CBL[1]:",compact_CBL[1],"--loose_CBL[0]",loose_CBL[1])
|
||||
|
||||
# 拷贝权重到剪枝后的模型中去
|
||||
tmp = loose_conv.weight.data[:, in_channel_idx, :, :].clone()
|
||||
compact_conv.weight.data = tmp[out_channel_idx, :, :, :].clone()
|
||||
|
||||
for idx in Conv_idx:
|
||||
|
||||
compact_conv = compact_model.module_list[idx][0]
|
||||
loose_conv = loose_model.module_list[idx][0]
|
||||
|
||||
# 虽然当前层是不带BN的卷积层,但仍然和上一个层的剪枝情况是相关的
|
||||
input_mask = get_input_mask(loose_model.module_defs, idx, CBLidx2mask)
|
||||
in_channel_idx = np.argwhere(input_mask)[:, 0].tolist()
|
||||
|
||||
# 拷贝权重到剪枝后的模型中去
|
||||
compact_conv.weight.data = loose_conv.weight.data[:, in_channel_idx, :, :].clone()
|
||||
compact_conv.bias.data = loose_conv.bias.data.clone()
|
||||
|
||||
|
||||
def prune_model_keep_size(model, prune_idx, CBL_idx, CBLidx2mask):
|
||||
# 先拷贝一份原始的模型参数
|
||||
pruned_model = deepcopy(model)
|
||||
# 对需要剪枝的层分别处理
|
||||
for idx in prune_idx:
|
||||
# 需要保留的通道
|
||||
mask = torch.from_numpy(CBLidx2mask[idx]).cuda()
|
||||
# 获取BN层的gamma参数,即BN层的权重
|
||||
bn_module = pruned_model.module_list[idx][1]
|
||||
# print("bn_module:", pruned_model.module_list[idx][1])
|
||||
|
||||
bn_module.weight.data.mul_(mask)
|
||||
# 获取保留下来的通道产生的激活值,注意是每个通道分别获取的
|
||||
activation = F.leaky_relu((1 - mask) * bn_module.bias.data, 0.1)
|
||||
|
||||
# 两个上采样层前的卷积层
|
||||
next_idx_list = [idx + 1]
|
||||
if idx == 79:
|
||||
next_idx_list.append(84)
|
||||
elif idx == 91:
|
||||
next_idx_list.append(96)
|
||||
|
||||
# print("idx:",idx,"--next_idx_list:",next_idx_list)
|
||||
|
||||
# 对下一层进行处理
|
||||
for next_idx in next_idx_list:
|
||||
# 当前层的BN剪枝之后会对下一个卷积层造成影响
|
||||
next_conv = pruned_model.module_list[next_idx][0]
|
||||
# dim=(2,3)即在(w,h)维度上进行求和,因为是通道剪枝,一个通道对应着(w,h)这个矩形
|
||||
conv_sum = next_conv.weight.data.sum(dim=(2, 3))
|
||||
# 将卷积层的权重和激活值相乘获得剪枝后的每个通道的偏置,以更新下一个BN层或者下一个带偏置的卷积层的偏执(因为单独的卷积层是不会被剪枝的,所以只对偏置有影响
|
||||
# print("idx:", {idx} , "| next_idx:" , {next_idx})
|
||||
# print("conv_sum :", conv_sum)
|
||||
# print("activation :", activation)
|
||||
# print("--------------------------")
|
||||
offset = conv_sum.matmul(activation.reshape(-1, 1)).reshape(-1)
|
||||
if next_idx in CBL_idx:
|
||||
next_bn = pruned_model.module_list[next_idx][1]
|
||||
next_bn.running_mean.data.sub_(offset)
|
||||
else:
|
||||
next_conv.bias.data.add_(offset)
|
||||
|
||||
bn_module.bias.data.mul_(mask)
|
||||
# 返回剪枝后的模型
|
||||
return pruned_model
|
||||
|
||||
|
||||
def obtain_bn_mask(bn_module, thre):
|
||||
|
||||
thre = thre.cuda()
|
||||
# ge(a, b)相当于 a>= b
|
||||
mask = bn_module.weight.data.abs().ge(thre).float()
|
||||
# print('thre = ',thre,"| mask = ", mask)
|
||||
|
||||
# 返回通道是否需要剪枝的通道状态
|
||||
return mask
|
||||
323
utils/utils.py
Normal file
323
utils/utils.py
Normal file
@ -0,0 +1,323 @@
|
||||
from __future__ import division
|
||||
import tqdm
|
||||
import torch
|
||||
import numpy as np
|
||||
import random
|
||||
|
||||
|
||||
def init_seeds(seed=0):
|
||||
random.seed(seed)
|
||||
np.random.seed(seed)
|
||||
torch.manual_seed(seed)
|
||||
torch.cuda.manual_seed(seed)
|
||||
torch.cuda.manual_seed_all(seed)
|
||||
|
||||
|
||||
def to_cpu(tensor):
|
||||
return tensor.detach().cpu()
|
||||
|
||||
|
||||
def load_classes(path):
|
||||
"""
|
||||
Loads class labels at 'path'
|
||||
"""
|
||||
fp = open(path, "r")
|
||||
names = fp.read().split("\n")[:-1]
|
||||
return names
|
||||
|
||||
|
||||
def weights_init_normal(m):
|
||||
classname = m.__class__.__name__
|
||||
if classname.find("Conv") != -1:
|
||||
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
|
||||
elif classname.find("BatchNorm2d") != -1:
|
||||
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
|
||||
torch.nn.init.constant_(m.bias.data, 0.0)
|
||||
|
||||
|
||||
def rescale_boxes(boxes, current_dim, original_shape):
|
||||
""" Rescales bounding boxes to the original shape """
|
||||
orig_h, orig_w = original_shape
|
||||
# The amount of padding that was added
|
||||
pad_x = max(orig_h - orig_w, 0) * (current_dim / max(original_shape))
|
||||
pad_y = max(orig_w - orig_h, 0) * (current_dim / max(original_shape))
|
||||
# Image height and width after padding is removed
|
||||
unpad_h = current_dim - pad_y
|
||||
unpad_w = current_dim - pad_x
|
||||
# Rescale bounding boxes to dimension of original image
|
||||
boxes[:, 0] = ((boxes[:, 0] - pad_x // 2) / unpad_w) * orig_w
|
||||
boxes[:, 1] = ((boxes[:, 1] - pad_y // 2) / unpad_h) * orig_h
|
||||
boxes[:, 2] = ((boxes[:, 2] - pad_x // 2) / unpad_w) * orig_w
|
||||
boxes[:, 3] = ((boxes[:, 3] - pad_y // 2) / unpad_h) * orig_h
|
||||
return boxes
|
||||
|
||||
|
||||
def xywh2xyxy(x):
|
||||
y = x.new(x.shape)
|
||||
y[..., 0] = x[..., 0] - x[..., 2] / 2
|
||||
y[..., 1] = x[..., 1] - x[..., 3] / 2
|
||||
y[..., 2] = x[..., 0] + x[..., 2] / 2
|
||||
y[..., 3] = x[..., 1] + x[..., 3] / 2
|
||||
return y
|
||||
|
||||
|
||||
def ap_per_class(tp, conf, pred_cls, target_cls):
|
||||
""" Compute the average precision, given the recall and precision curves.
|
||||
Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
|
||||
# Arguments
|
||||
tp: True positives (list).
|
||||
conf: Objectness value from 0-1 (list).
|
||||
pred_cls: Predicted object classes (list).
|
||||
target_cls: True object classes (list).
|
||||
# Returns
|
||||
The average precision as computed in py-faster-rcnn.
|
||||
"""
|
||||
|
||||
# Sort by objectness
|
||||
i = np.argsort(-conf)
|
||||
tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
|
||||
|
||||
# Find unique classes
|
||||
unique_classes = np.unique(target_cls)
|
||||
|
||||
# Create Precision-Recall curve and compute AP for each class
|
||||
ap, p, r = [], [], []
|
||||
for c in tqdm.tqdm(unique_classes, desc="Computing AP"):
|
||||
i = pred_cls == c
|
||||
n_gt = (target_cls == c).sum() # Number of ground truth objects
|
||||
n_p = i.sum() # Number of predicted objects
|
||||
|
||||
if n_p == 0 and n_gt == 0:
|
||||
continue
|
||||
elif n_p == 0 or n_gt == 0:
|
||||
ap.append(0)
|
||||
r.append(0)
|
||||
p.append(0)
|
||||
else:
|
||||
# Accumulate FPs and TPs
|
||||
fpc = (1 - tp[i]).cumsum()
|
||||
tpc = (tp[i]).cumsum()
|
||||
|
||||
# Recall
|
||||
recall_curve = tpc / (n_gt + 1e-16)
|
||||
r.append(recall_curve[-1])
|
||||
|
||||
# Precision
|
||||
precision_curve = tpc / (tpc + fpc)
|
||||
p.append(precision_curve[-1])
|
||||
|
||||
# AP from recall-precision curve
|
||||
ap.append(compute_ap(recall_curve, precision_curve))
|
||||
|
||||
# Compute F1 score (harmonic mean of precision and recall)
|
||||
p, r, ap = np.array(p), np.array(r), np.array(ap)
|
||||
f1 = 2 * p * r / (p + r + 1e-16)
|
||||
|
||||
return p, r, ap, f1, unique_classes.astype("int32")
|
||||
|
||||
|
||||
def compute_ap(recall, precision):
|
||||
""" Compute the average precision, given the recall and precision curves.
|
||||
Code originally from https://github.com/rbgirshick/py-faster-rcnn.
|
||||
|
||||
# Arguments
|
||||
recall: The recall curve (list).
|
||||
precision: The precision curve (list).
|
||||
# Returns
|
||||
The average precision as computed in py-faster-rcnn.
|
||||
"""
|
||||
# correct AP calculation
|
||||
# first append sentinel values at the end
|
||||
mrec = np.concatenate(([0.0], recall, [1.0]))
|
||||
mpre = np.concatenate(([0.0], precision, [0.0]))
|
||||
|
||||
# compute the precision envelope
|
||||
for i in range(mpre.size - 1, 0, -1):
|
||||
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
|
||||
|
||||
# to calculate area under PR curve, look for points
|
||||
# where X axis (recall) changes value
|
||||
i = np.where(mrec[1:] != mrec[:-1])[0]
|
||||
|
||||
# and sum (\Delta recall) * prec
|
||||
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
|
||||
return ap
|
||||
|
||||
|
||||
def get_batch_statistics(outputs, targets, iou_threshold):
|
||||
""" Compute true positives, predicted scores and predicted labels per sample """
|
||||
batch_metrics = []
|
||||
for sample_i in range(len(outputs)):
|
||||
|
||||
if outputs[sample_i] is None:
|
||||
continue
|
||||
|
||||
output = outputs[sample_i] # 取出结果
|
||||
pred_boxes = output[:, :4] # box
|
||||
pred_scores = output[:, 4] # 置信度
|
||||
pred_labels = output[:, -1]# 类别
|
||||
|
||||
true_positives = np.zeros(pred_boxes.shape[0]) # 统计postive的值
|
||||
|
||||
annotations = targets[targets[:, 0] == sample_i][:, 1:] # 取出对应的图片的 标注【label,x,y,w,h】
|
||||
target_labels = annotations[:, 0] if len(annotations) else [] # 取出图片内的 label
|
||||
if len(annotations):
|
||||
detected_boxes = []
|
||||
target_boxes = annotations[:, 1:] # 标注bbox
|
||||
|
||||
for pred_i, (pred_box, pred_label) in enumerate(zip(pred_boxes, pred_labels)):
|
||||
|
||||
# If targets are found break
|
||||
if len(detected_boxes) == len(annotations): # 完成图片内的目标检测
|
||||
break
|
||||
|
||||
# Ignore if label is not one of the target labels
|
||||
if pred_label not in target_labels:
|
||||
continue
|
||||
|
||||
iou, box_index = bbox_iou(pred_box.unsqueeze(0), target_boxes).max(0) # 返回列最大值
|
||||
if iou >= iou_threshold and box_index not in detected_boxes: # iou>阈值的
|
||||
true_positives[pred_i] = 1
|
||||
detected_boxes += [box_index]
|
||||
batch_metrics.append([true_positives, pred_scores, pred_labels])
|
||||
return batch_metrics
|
||||
|
||||
|
||||
def bbox_wh_iou(wh1, wh2):
|
||||
wh2 = wh2.t()
|
||||
w1, h1 = wh1[0], wh1[1]
|
||||
w2, h2 = wh2[0], wh2[1]
|
||||
inter_area = torch.min(w1, w2) * torch.min(h1, h2)
|
||||
union_area = (w1 * h1 + 1e-16) + w2 * h2 - inter_area
|
||||
return inter_area / union_area
|
||||
|
||||
|
||||
def bbox_iou(box1, box2, x1y1x2y2=True):
|
||||
"""
|
||||
Returns the IoU of two bounding boxes
|
||||
"""
|
||||
if not x1y1x2y2:
|
||||
# Transform from center and width to exact coordinates
|
||||
b1_x1, b1_x2 = box1[:, 0] - box1[:, 2] / 2, box1[:, 0] + box1[:, 2] / 2
|
||||
b1_y1, b1_y2 = box1[:, 1] - box1[:, 3] / 2, box1[:, 1] + box1[:, 3] / 2
|
||||
b2_x1, b2_x2 = box2[:, 0] - box2[:, 2] / 2, box2[:, 0] + box2[:, 2] / 2
|
||||
b2_y1, b2_y2 = box2[:, 1] - box2[:, 3] / 2, box2[:, 1] + box2[:, 3] / 2
|
||||
else:
|
||||
# Get the coordinates of bounding boxes
|
||||
b1_x1, b1_y1, b1_x2, b1_y2 = box1[:, 0], box1[:, 1], box1[:, 2], box1[:, 3]
|
||||
b2_x1, b2_y1, b2_x2, b2_y2 = box2[:, 0], box2[:, 1], box2[:, 2], box2[:, 3]
|
||||
|
||||
# get the corrdinates of the intersection rectangle
|
||||
inter_rect_x1 = torch.max(b1_x1, b2_x1)
|
||||
inter_rect_y1 = torch.max(b1_y1, b2_y1)
|
||||
inter_rect_x2 = torch.min(b1_x2, b2_x2)
|
||||
inter_rect_y2 = torch.min(b1_y2, b2_y2)
|
||||
# Intersection area
|
||||
inter_area = torch.clamp(inter_rect_x2 - inter_rect_x1 + 1, min=0) * torch.clamp(
|
||||
inter_rect_y2 - inter_rect_y1 + 1, min=0
|
||||
)
|
||||
# Union Area
|
||||
b1_area = (b1_x2 - b1_x1 + 1) * (b1_y2 - b1_y1 + 1)
|
||||
b2_area = (b2_x2 - b2_x1 + 1) * (b2_y2 - b2_y1 + 1)
|
||||
|
||||
iou = inter_area / (b1_area + b2_area - inter_area + 1e-16)
|
||||
|
||||
return iou
|
||||
|
||||
|
||||
def non_max_suppression(prediction, conf_thres=0.5, nms_thres=0.4):
|
||||
"""
|
||||
Removes detections with lower object confidence score than 'conf_thres' and performs
|
||||
Non-Maximum Suppression to further filter detections.
|
||||
Returns detections with shape:
|
||||
(x1, y1, x2, y2, object_conf, class_score, class_pred)
|
||||
"""
|
||||
|
||||
# From (center x, center y, width, height) to (x1, y1, x2, y2)
|
||||
prediction[..., :4] = xywh2xyxy(prediction[..., :4])
|
||||
output = [None for _ in range(len(prediction))]
|
||||
for image_i, image_pred in enumerate(prediction):
|
||||
# Filter out confidence scores below threshold
|
||||
image_pred = image_pred[image_pred[:, 4] >= conf_thres]
|
||||
# If none are remaining => process next image
|
||||
if not image_pred.size(0):
|
||||
continue
|
||||
# Object confidence times class confidence
|
||||
score = image_pred[:, 4] * image_pred[:, 5:].max(1)[0]
|
||||
# Sort by it
|
||||
image_pred = image_pred[(-score).argsort()]
|
||||
class_confs, class_preds = image_pred[:, 5:].max(1, keepdim=True)
|
||||
detections = torch.cat((image_pred[:, :5], class_confs.float(), class_preds.float()), 1)
|
||||
# Perform non-maximum suppression
|
||||
keep_boxes = []
|
||||
while detections.size(0):
|
||||
large_overlap = bbox_iou(detections[0, :4].unsqueeze(0), detections[:, :4]) > nms_thres
|
||||
label_match = detections[0, -1] == detections[:, -1]
|
||||
# Indices of boxes with lower confidence scores, large IOUs and matching labels
|
||||
invalid = large_overlap & label_match
|
||||
weights = detections[invalid, 4:5]
|
||||
# Merge overlapping bboxes by order of confidence
|
||||
detections[0, :4] = (weights * detections[invalid, :4]).sum(0) / weights.sum()
|
||||
keep_boxes += [detections[0]]
|
||||
detections = detections[~invalid]
|
||||
if keep_boxes:
|
||||
output[image_i] = torch.stack(keep_boxes)
|
||||
|
||||
return output
|
||||
|
||||
|
||||
def build_targets(pred_boxes, pred_cls, target, anchors, ignore_thres):
|
||||
|
||||
ByteTensor = torch.cuda.ByteTensor if pred_boxes.is_cuda else torch.ByteTensor
|
||||
FloatTensor = torch.cuda.FloatTensor if pred_boxes.is_cuda else torch.FloatTensor
|
||||
|
||||
nB = pred_boxes.size(0) # num_samples, num_anchors, grid_size, grid_size, 4
|
||||
nA = pred_boxes.size(1)
|
||||
nC = pred_cls.size(-1) # num_samples, num_anchors, grid_size, grid_size, num_classes
|
||||
nG = pred_boxes.size(2)
|
||||
|
||||
# Output tensors
|
||||
obj_mask = ByteTensor(nB, nA, nG, nG).fill_(0)
|
||||
noobj_mask = ByteTensor(nB, nA, nG, nG).fill_(1)
|
||||
class_mask = FloatTensor(nB, nA, nG, nG).fill_(0)
|
||||
iou_scores = FloatTensor(nB, nA, nG, nG).fill_(0)
|
||||
tx = FloatTensor(nB, nA, nG, nG).fill_(0)
|
||||
ty = FloatTensor(nB, nA, nG, nG).fill_(0)
|
||||
tw = FloatTensor(nB, nA, nG, nG).fill_(0)
|
||||
th = FloatTensor(nB, nA, nG, nG).fill_(0)
|
||||
tcls = FloatTensor(nB, nA, nG, nG, nC).fill_(0)
|
||||
|
||||
# Convert to position relative to box
|
||||
target_boxes = target[:, 2:6] * nG # target的1维是其对应图片的idx
|
||||
gxy = target_boxes[:, :2]
|
||||
gwh = target_boxes[:, 2:]
|
||||
# Get anchors with best iou
|
||||
ious = torch.stack([bbox_wh_iou(anchor, gwh) for anchor in anchors]) # anchors*target
|
||||
best_ious, best_n = ious.max(0)
|
||||
# Separate target values
|
||||
b, target_labels = target[:, :2].long().t() # target = [idx, labels, x, y, w, h]
|
||||
gx, gy = gxy.t()
|
||||
gw, gh = gwh.t()
|
||||
gi, gj = gxy.long().t() # long是变成长整型
|
||||
# Set masks
|
||||
obj_mask[b, best_n, gj, gi] = 1
|
||||
noobj_mask[b, best_n, gj, gi] = 0
|
||||
|
||||
# Set noobj mask to zero where iou exceeds ignore threshold
|
||||
for i, anchor_ious in enumerate(ious.t()):
|
||||
noobj_mask[b[i], anchor_ious > ignore_thres, gj[i], gi[i]] = 0
|
||||
|
||||
# Coordinates
|
||||
tx[b, best_n, gj, gi] = gx - gx.floor()
|
||||
ty[b, best_n, gj, gi] = gy - gy.floor()
|
||||
# Width and height
|
||||
tw[b, best_n, gj, gi] = torch.log(gw / anchors[best_n][:, 0] + 1e-16)
|
||||
th[b, best_n, gj, gi] = torch.log(gh / anchors[best_n][:, 1] + 1e-16)
|
||||
# One-hot encoding of label
|
||||
tcls[b, best_n, gj, gi, target_labels] = 1
|
||||
# Compute label correctness and iou at best anchor
|
||||
class_mask[b, best_n, gj, gi] = (pred_cls[b, best_n, gj, gi].argmax(-1) == target_labels).float()
|
||||
iou_scores[b, best_n, gj, gi] = bbox_iou(pred_boxes[b, best_n, gj, gi], target_boxes, x1y1x2y2=False)
|
||||
|
||||
tconf = obj_mask.float()
|
||||
return iou_scores, class_mask, obj_mask, noobj_mask, tx, ty, tw, th, tcls, tconf
|
||||
4
xs_train.sh
Normal file
4
xs_train.sh
Normal file
@ -0,0 +1,4 @@
|
||||
#!bash
|
||||
CARD=0,1
|
||||
|
||||
CUDA_VISIBLE_DEVICES=$CARD python train.py --model_def config/yolov3-person.cfg -sr --s 0.01
|
||||
Loading…
x
Reference in New Issue
Block a user